Semantic Kernel/C# をフロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるか?
未だ Semantic Kernel を勉強中の身ですが、C# でもベクトルデータを利用できるコードを書けるのは非常にナイスです。Python 側も当然強力な言語ですが、Web でのフロントエンド構築を含むユーザインタフェースを作成する際は C# 等を利用することが多い認識です。以下の記事で C# での Azure OpenAI 利用を試しましたが、C# を利用することで様々な Azure 機能と連携しやすくなるのも大きな利点あり、個人的には特に Azure 上で Application Insights 等のロギングライブラリと連携が容易になる点が魅力的です。
normalian.hatenablog.com
今回は Azure PostgreSQL をデータストアとして Semantic Kernel/C# が フロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるかということを検証したいと思います。
LangChain/Python 側でドキュメントをベクトルデータ化して PosgreSQL に保存する
さっそく利用したソースコードの紹介となりますが、以下となります。もともと Azure Cognitive Search 側で利用していたソースコードを PosgreSQL に変えただけです。
import os import re from typing import List, Tuple from dotenv import load_dotenv from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores.pgvector import PGVector from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import TokenTextSplitter, TextSplitter import hashlib deployment="text-embedding-ada-002" chunk_size=1 openai_api_type="azure" openai_api_key="your-azure-openai-key" openai_api_base="https://your-azure-openai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) # このコレクション名がデータストア時に反映されない、なぜだ… COLLECTION_NAME = "test02" CONNECTION_STRING = PGVector.connection_string_from_db_params( driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"), host=os.environ.get("PGVECTOR_HOST", "your-severname.postgres.database.azure.com"), port=int(os.environ.get("PGVECTOR_PORT", "5432")), database=os.environ.get("PGVECTOR_DATABASE", "database-name"), user=os.environ.get("PGVECTOR_USER", "your-username"), password=os.environ.get("PGVECTOR_PASSWORD", "your-password"), # パスワードに @ を含めると文字列パースでエラーになった(汗 ) vector_store = PGVector( collection_name=COLLECTION_NAME, connection_string=CONNECTION_STRING, embedding_function=embeddings, ) source_url = 'https://your-blobstorage-account.blob.core.windows.net/your-document' print("############# start #1 ") chunk_size = 400 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents) print("############# start #2 ") # Remove half non-ascii character from start/end of doc content (langchain TokenTextSplitter may split a non-ascii character in half) # Azure Cognitive Search だと要らなかったが、PosgreSQL だと必要だった pattern = re.compile(r'[\x00-\x09\x0b\x0c\x0e-\x1f\x7f\u0080-\u00a0\u2000-\u3000\ufff0-\uffff]') # do not remove \x0a (\n) nor \x0d (\r) for(doc) in docs: doc.page_content = re.sub(pattern, '', doc.page_content) if doc.page_content == '': docs.remove(doc) keys = [] for i, doc in enumerate(docs): # Create a unique key for the document # print(doc) source_url = source_url.split('?')[0] filename = "/".join(source_url.split('/')[4:]) hash_key = hashlib.sha1(f"{source_url}_{i}".encode('utf-8')).hexdigest() hash_key = f"doc:{COLLECTION_NAME}:{hash_key}" keys.append(hash_key) doc.metadata = {"source": f"[{source_url}]({source_url}_SAS_TOKEN_PLACEHOLDER_)" , "chunk": i, "key": hash_key, "filename": filename} print("############# start #3 ") vector_store.add_documents(documents=docs) print("############# end")
ソースコード内に色々と TIPS を記載しましたが、特殊文字処理が必要など、いくつかの対応が必要でした。上記のソースコードを実行すると以下の様に public."langchain_pg_collection" と public.langchain_pg_embedding という二つのスキーマが PosgreSQL 上に作成されます。スキーマの詳細については以下を参照下さい。
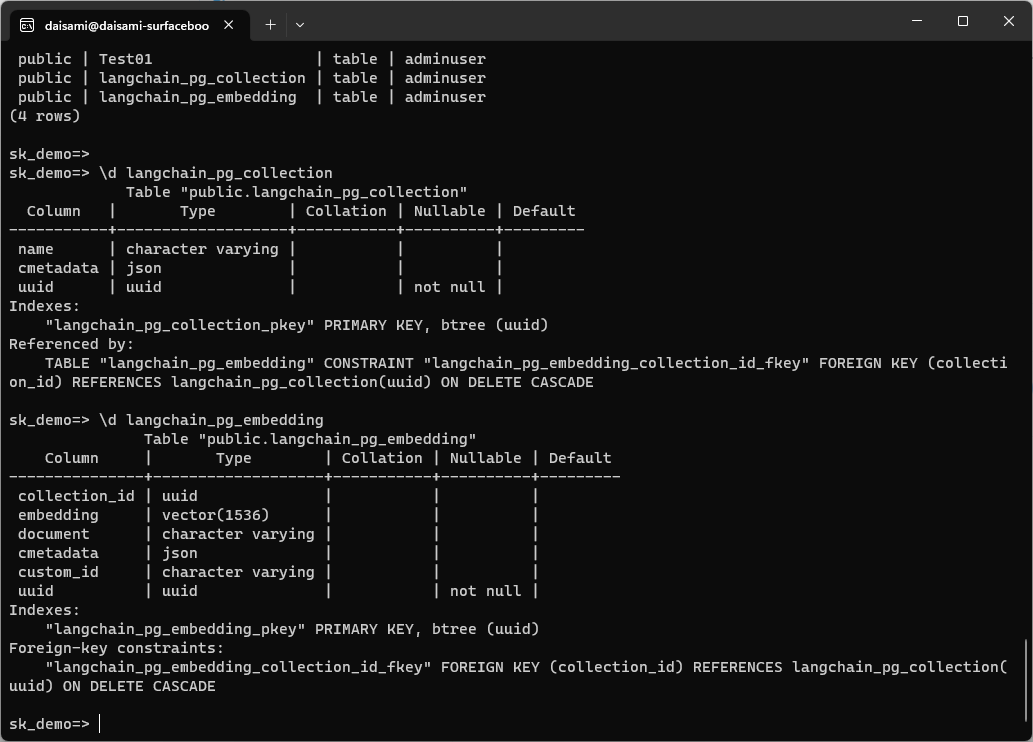
LangChain/Python の場合に作成されるスキーマ名を調べたところ、以下の様にハードコードされている箇所がありました。
github.com
なぜ collection 名を指定しても反映されなかったのかはやや腑に落ちませんが、本題ではないので話題を先に進めたいと思います。
ベクトル形式でドキュメントがデータストアに格納されたので、次に Sematic Kernel 側で C# のソースコードを書いてみました。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Memory.Postgres;
using Microsoft.SemanticKernel.Memory;
using Npgsql;
using Pgvector.Npgsql;
namespace MyOpenAITest
{
class Program
{
public static async Task Main(string[] args) {
// Azure OpenAI parameters
const string deploymentName_chat = "text-davinci-003";
const string endpoint = "https://your-azureopenai-endpoint.openai.azure.com/";
const string openAiKey = "your-azureopenai-key";
const string deploymentName_embedding = "text-embedding-ada-002";
// posgresql connection string
const string connectionString = "Host=your-posgresql-servername.postgres.database.azure.com;Port=5432;Database=your-dbname;User Id=your-usename;Password=your-password";
Console.WriteLine("== Start Applicaiton ==");
NpgsqlDataSourceBuilder dataSourceBuilder = new NpgsqlDataSourceBuilder(connectionString);
dataSourceBuilder.UseVector();
NpgsqlDataSource dataSource = dataSourceBuilder.Build();
PostgresMemoryStore memoryStore = new PostgresMemoryStore(dataSource, vectorSize: 1536/*, schema: "public" */);
IKernel kernel = Kernel.Builder
// .WithLogger(ConsoleLogger.Log)
.WithAzureTextCompletionService(deploymentName_chat, endpoint, openAiKey)
.WithAzureTextEmbeddingGenerationService(deploymentName_embedding, endpoint, openAiKey)
.WithMemoryStorage(memoryStore)
.WithPostgresMemoryStore(dataSource, vectorSize: 1536, schema: "public")
.Build();
string ask = "How can I Associate EA and CSP subscriptions into same AAD tenant?";
Console.WriteLine("===========================\n" +
"Query: " + ask + "\n");
var memories = kernel.Memory.SearchAsync("langchain_pg_collection", ask, limit: 5, minRelevanceScore: 0.77);
int j = 0;
await foreach (MemoryQueryResult memory in memories)
{
Console.WriteLine($"Result {++j}:");
Console.WriteLine(" URL: : " + memory.Metadata.Id);
Console.WriteLine(" Title : " + memory.Metadata.Description);
Console.WriteLine(" Relevance: " + memory.Relevance);
Console.WriteLine();
}
Console.WriteLine("== End Application ==");
}
}
}上記を実行すると以下の様に '42703: column "key" does not exist というエラーが発生します。どうやら key という column が無いようです。
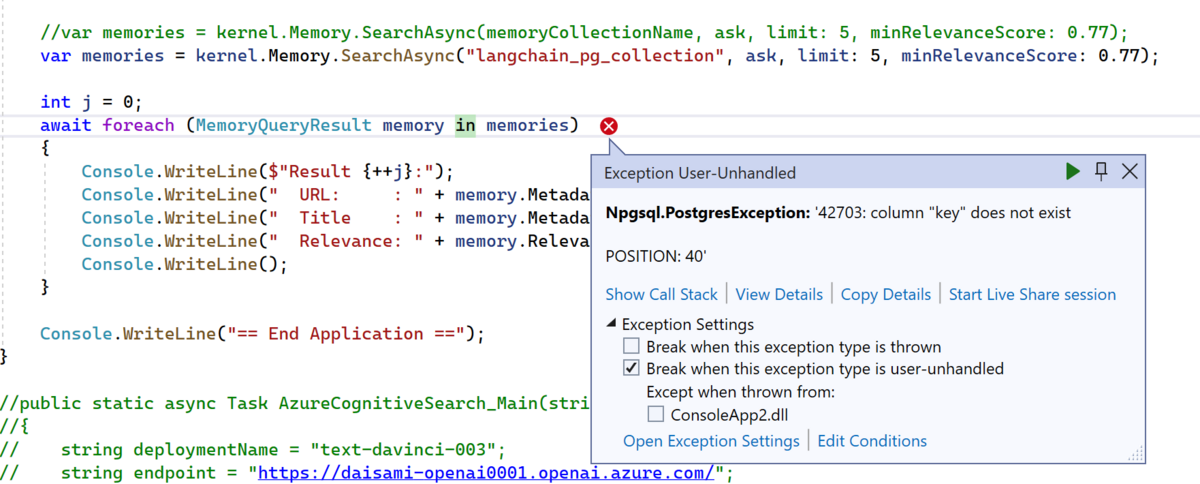
この結果から、Semantic Kernel/C# と LangChain/Python ではベクトルストアへのデータ格納時にスキーマが異なるのではとの推察をしました。
Semantic Kernel/C# 側でベクトルデータを PosgreSQL に格納してスキーマを確認する
次に Semantic Kernel/C# 側でベクトルデータを PosgreSQL に格納してみます。以下の様に GitHub のドキュメント文字列をベクトル化し、ベクトルデータストア(この場合は PosgreSQL)に格納します。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Memory.Postgres;
using Microsoft.SemanticKernel.Memory;
using Npgsql;
using Pgvector.Npgsql;
namespace MyOpenAITest
{
class Program
{
public static async Task Main(string[] args)
{
// Azure OpenAI parameters
const string deploymentName_chat = "text-davinci-003";
const string endpoint = "https://your-azureopenai-endpoint.openai.azure.com/";
const string openAiKey = "your-azureopenai-key";
const string deploymentName_embedding = "text-embedding-ada-002";
// posgresql connection string
const string connectionString = "Host=your-posgresql-endpoint.postgres.database.azure.com;Port=5432;Database=sk_demo;User Id=your-posgresql-username;Password=your-posgresql-password";
Console.WriteLine("== Start Applicaiton ==");
NpgsqlDataSourceBuilder dataSourceBuilder = new NpgsqlDataSourceBuilder(connectionString);
dataSourceBuilder.UseVector();
NpgsqlDataSource dataSource = dataSourceBuilder.Build();
PostgresMemoryStore memoryStore = new PostgresMemoryStore(dataSource, vectorSize: 1536/*, schema: "public" */);
IKernel kernel = Kernel.Builder
// .WithLogger(ConsoleLogger.Log)
.WithAzureTextCompletionService(deploymentName_chat, endpoint, openAiKey)
.WithAzureTextEmbeddingGenerationService(deploymentName_embedding, endpoint, openAiKey)
.WithMemoryStorage(memoryStore)
.WithPostgresMemoryStore(dataSource, vectorSize: 1536, schema: "public")
.Build();
const string memoryCollectionName = "SKGitHub";
var githubFiles = new Dictionary<string, string>()
{
["https://github.com/microsoft/semantic-kernel/blob/main/README.md"]
= "README: Installation, getting started, and how to contribute",
["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/02-running-prompts-from-file.ipynb"]
= "Jupyter notebook describing how to pass prompts from a file to a semantic skill or function",
["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/00-getting-started.ipynb"]
= "Jupyter notebook describing how to get started with the Semantic Kernel",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/skills/ChatSkill/ChatGPT"]
= "Sample demonstrating how to create a chat skill interfacing with ChatGPT",
["https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/SemanticKernel/Memory/Volatile/VolatileMemoryStore.cs"]
= "C# class that defines a volatile embedding store",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/dotnet/KernelHttpServer/README.md"]
= "README: How to set up a Semantic Kernel Service API using Azure Function Runtime v4",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/apps/chat-summary-webapp-react/README.md"]
= "README: README associated with a sample starter react-based chat summary webapp",
};
Console.WriteLine("Adding some GitHub file URLs and their descriptions to a volatile Semantic Memory.");
int i = 0;
foreach (var entry in githubFiles)
{
await kernel.Memory.SaveReferenceAsync(
collection: memoryCollectionName,
description: entry.Value,
text: entry.Value,
externalId: entry.Key,
externalSourceName: "GitHub"
);
Console.WriteLine($" URL {++i} saved");
}
string ask = "How can I Associate EA and CSP subscriptions into same AAD tenant?";
Console.WriteLine("===========================\n" +
"Query: " + ask + "\n");
var memories = kernel.Memory.SearchAsync(memoryCollectionName, ask, limit: 5, minRelevanceScore: 0.77);
//var memories = kernel.Memory.SearchAsync("langchain_pg_collection", ask, limit: 5, minRelevanceScore: 0.77);
int j = 0;
await foreach (MemoryQueryResult memory in memories)
{
Console.WriteLine($"Result {++j}:");
Console.WriteLine(" URL: : " + memory.Metadata.Id);
Console.WriteLine(" Title : " + memory.Metadata.Description);
Console.WriteLine(" Relevance: " + memory.Relevance);
Console.WriteLine();
}
Console.WriteLine("== End Application ==");
}
}
}上記を実行後、PosgreSQL に接続した結果、スキーマは以下の様になりました。御覧の通り、Semantic Kernel 側で作成したスキーマには text 型のデータを格納する key という名前のカラムが存在しますが、LangChain 側には存在しないカラムなことが分かります。

そのほかにも、embedding されたデータを格納するカラムのデータ型・カラム名は同じなことは分かりますが、その他は異なるカラムでのデータが格納されていることが分かると思います。
「Semantic Kernel/C# をフロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるか?」の結論
本ポストの掲題でもあったテーマについては、実現は難しいというのが結論になると思います。両ライブラリで格納されたベクトルデータだけは同じですが、他のカラム等々は異なるデータ形式で格納されているので、現実的にはこちらを上手くマッピングさせて相互運用というのは難しいのではと考えています。
上記に加え、「既に PosgreSQL に格納されているベクトル化データをそのまま別のデータストア(Azure Cognitive Search 等)に移行したい」というベクトルデータの格納コンポーネントを変えるという処理も、今回の結果を踏まえれば難しいという推察ができます。データのマッピングを考えるより、新しくベクトル化データを作り直す方が現実的でしょう。
結果的に期待を満たすのでなく、実現が難しいという知見を得るにとどまってしまいましたが、こちらの検証結果が皆様のお役に立てば幸いです。