Azure Files のプライベートエンドポイントの IP アドレスを固定にする
今回は掲題のテーマを備忘録程度に記載したいと思います。ご存じの方はいらっしゃると思いますが、プライベートエンドポイントで固定 IP を振ることができる機能が2022年10月時点で提供されております。
azure.microsoft.com
しかし、たまたまポータルで Azure Files のにプライベートエンドポイントを作成したら固定 IP アドレスが割り振れず(嘘でした。追記を参照下さい)、作成後は IP アドレスが変更できませんでした。その結果、コマンドで試したら固定 IP が割り振れたので、以下の私が利用したスクリプトを備忘録的に張り付けておきます。
$resourcegroupname="xxxxxxxxx"
$storageaccountname="xxxxxxxxx"
$vnetname="xxxxxxxxx"
$subnetname="xxxxxxxxx"
storageAccountId=$(az storage account show --name $storageaccountname --resource-group $resourcegroupname --query "id" --output tsv)
az network private-endpoint create \
--name "myendpoint" \
--resource-group $resourcegroupname \
--vnet-name $vnetname \
--subnet $subnetname \
--private-connection-resource-id $storageAccountId \
--group-id file \
--connection-name "myConnection" \
--ip-config name=ipconfig-1 group-id=file member-name=file private-ip-address=10.0.1.10 \上記のスクリプトを実行すると以下の様にポータル上で IP アドレスが固定になっていることが確認できます。ご参考まで。
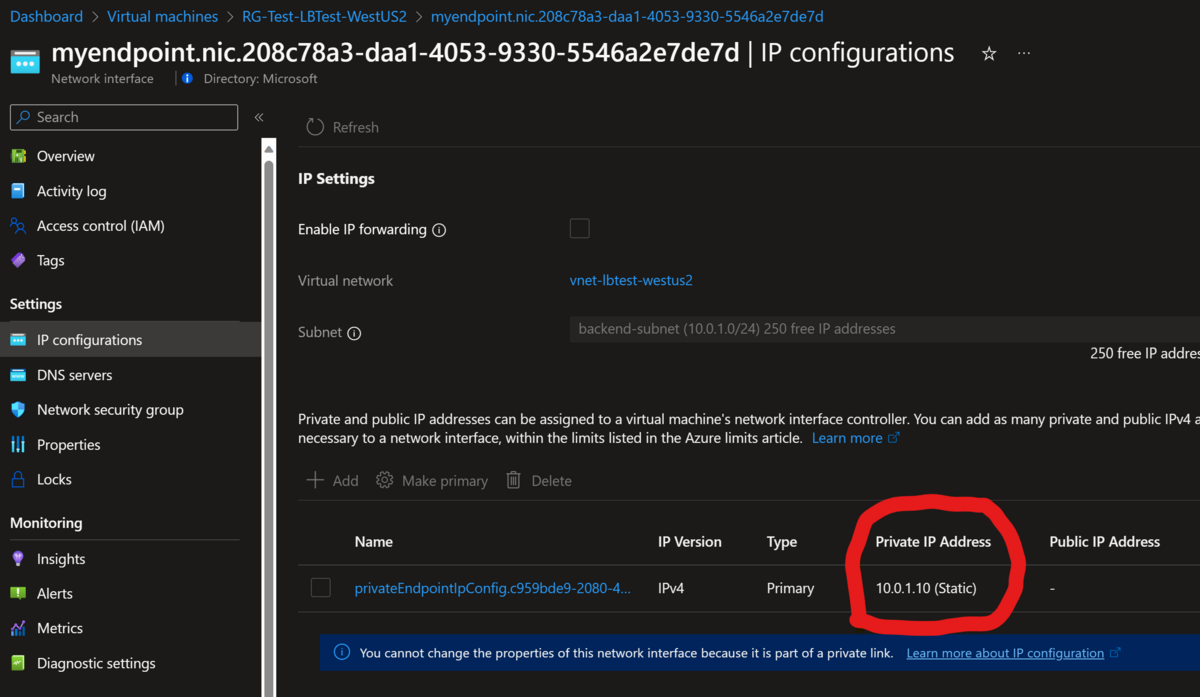
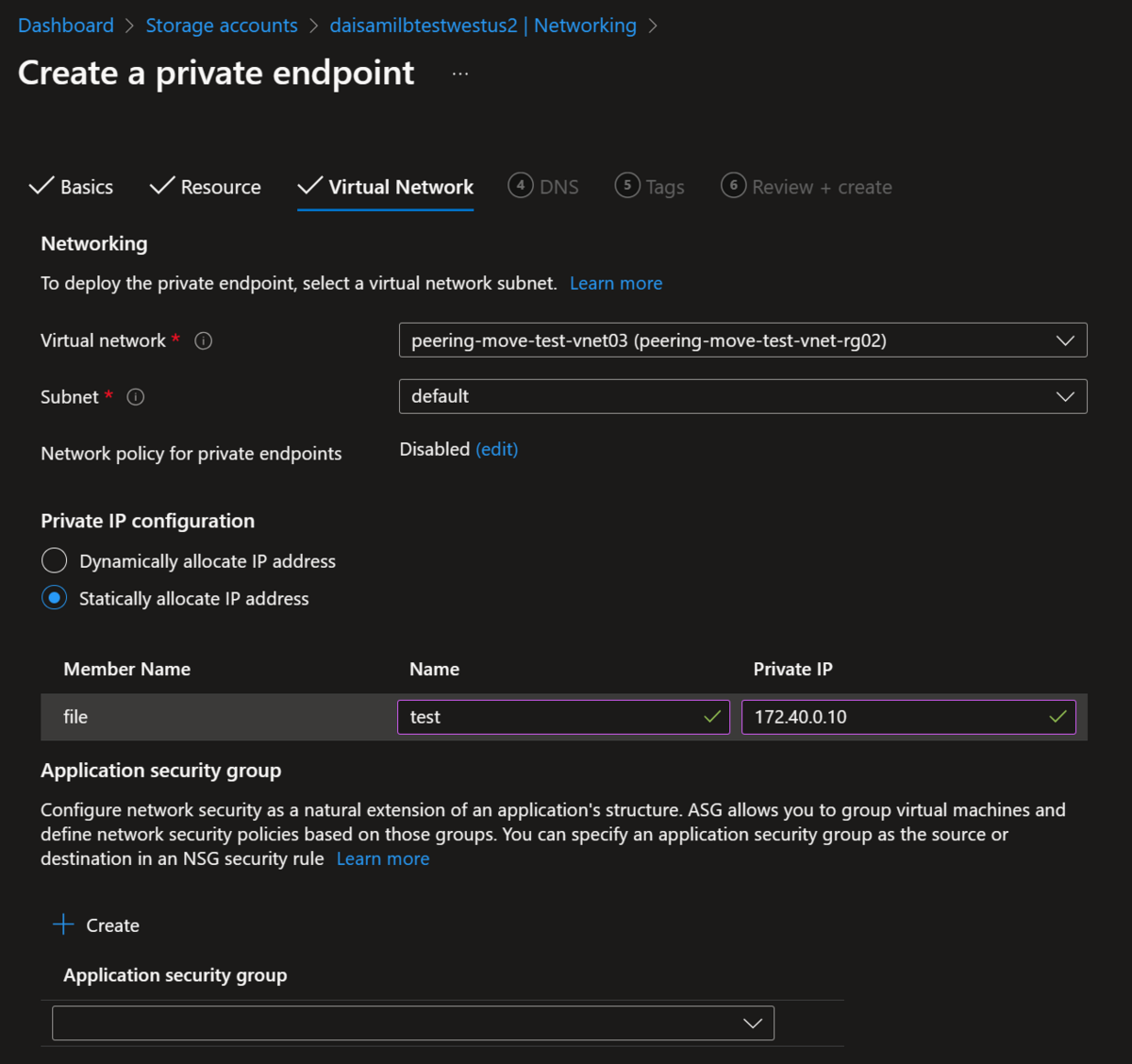
追記:後で確認したら以下の様にポータルで設定できました(汗
Semantic Kernel/C# をフロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるか?
未だ Semantic Kernel を勉強中の身ですが、C# でもベクトルデータを利用できるコードを書けるのは非常にナイスです。Python 側も当然強力な言語ですが、Web でのフロントエンド構築を含むユーザインタフェースを作成する際は C# 等を利用することが多い認識です。以下の記事で C# での Azure OpenAI 利用を試しましたが、C# を利用することで様々な Azure 機能と連携しやすくなるのも大きな利点あり、個人的には特に Azure 上で Application Insights 等のロギングライブラリと連携が容易になる点が魅力的です。
normalian.hatenablog.com
今回は Azure PostgreSQL をデータストアとして Semantic Kernel/C# が フロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるかということを検証したいと思います。
LangChain/Python 側でドキュメントをベクトルデータ化して PosgreSQL に保存する
さっそく利用したソースコードの紹介となりますが、以下となります。もともと Azure Cognitive Search 側で利用していたソースコードを PosgreSQL に変えただけです。
import os import re from typing import List, Tuple from dotenv import load_dotenv from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores.pgvector import PGVector from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import TokenTextSplitter, TextSplitter import hashlib deployment="text-embedding-ada-002" chunk_size=1 openai_api_type="azure" openai_api_key="your-azure-openai-key" openai_api_base="https://your-azure-openai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) # このコレクション名がデータストア時に反映されない、なぜだ… COLLECTION_NAME = "test02" CONNECTION_STRING = PGVector.connection_string_from_db_params( driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"), host=os.environ.get("PGVECTOR_HOST", "your-severname.postgres.database.azure.com"), port=int(os.environ.get("PGVECTOR_PORT", "5432")), database=os.environ.get("PGVECTOR_DATABASE", "database-name"), user=os.environ.get("PGVECTOR_USER", "your-username"), password=os.environ.get("PGVECTOR_PASSWORD", "your-password"), # パスワードに @ を含めると文字列パースでエラーになった(汗 ) vector_store = PGVector( collection_name=COLLECTION_NAME, connection_string=CONNECTION_STRING, embedding_function=embeddings, ) source_url = 'https://your-blobstorage-account.blob.core.windows.net/your-document' print("############# start #1 ") chunk_size = 400 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents) print("############# start #2 ") # Remove half non-ascii character from start/end of doc content (langchain TokenTextSplitter may split a non-ascii character in half) # Azure Cognitive Search だと要らなかったが、PosgreSQL だと必要だった pattern = re.compile(r'[\x00-\x09\x0b\x0c\x0e-\x1f\x7f\u0080-\u00a0\u2000-\u3000\ufff0-\uffff]') # do not remove \x0a (\n) nor \x0d (\r) for(doc) in docs: doc.page_content = re.sub(pattern, '', doc.page_content) if doc.page_content == '': docs.remove(doc) keys = [] for i, doc in enumerate(docs): # Create a unique key for the document # print(doc) source_url = source_url.split('?')[0] filename = "/".join(source_url.split('/')[4:]) hash_key = hashlib.sha1(f"{source_url}_{i}".encode('utf-8')).hexdigest() hash_key = f"doc:{COLLECTION_NAME}:{hash_key}" keys.append(hash_key) doc.metadata = {"source": f"[{source_url}]({source_url}_SAS_TOKEN_PLACEHOLDER_)" , "chunk": i, "key": hash_key, "filename": filename} print("############# start #3 ") vector_store.add_documents(documents=docs) print("############# end")
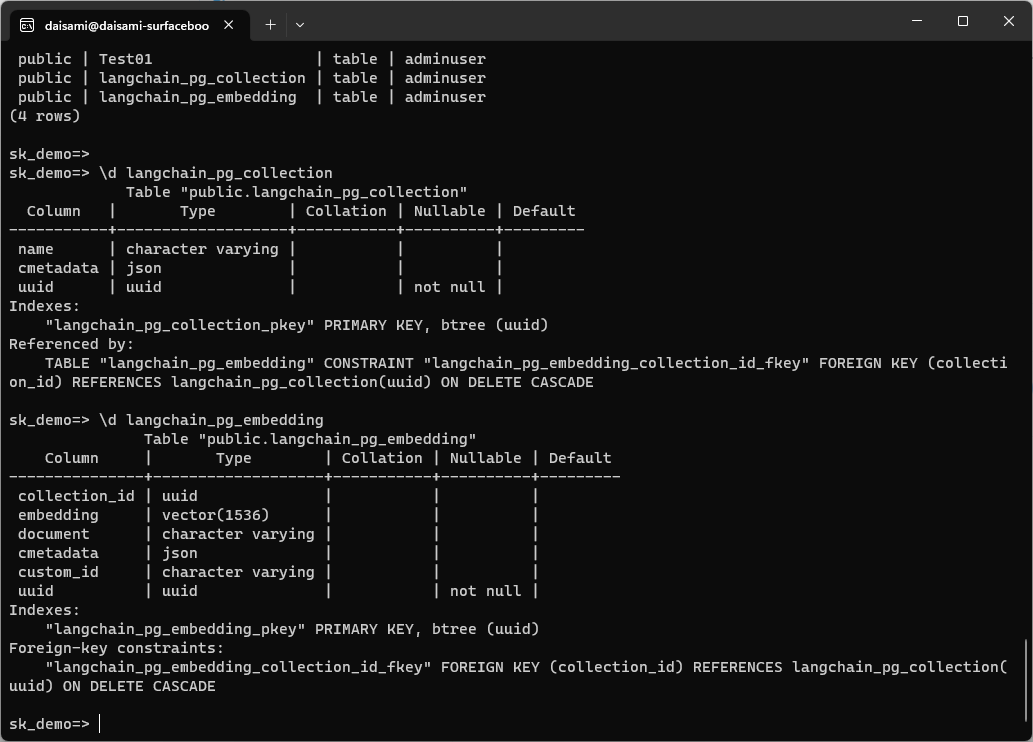
ソースコード内に色々と TIPS を記載しましたが、特殊文字処理が必要など、いくつかの対応が必要でした。上記のソースコードを実行すると以下の様に public."langchain_pg_collection" と public.langchain_pg_embedding という二つのスキーマが PosgreSQL 上に作成されます。スキーマの詳細については以下を参照下さい。
LangChain/Python の場合に作成されるスキーマ名を調べたところ、以下の様にハードコードされている箇所がありました。
github.com
なぜ collection 名を指定しても反映されなかったのかはやや腑に落ちませんが、本題ではないので話題を先に進めたいと思います。
ベクトル形式でドキュメントがデータストアに格納されたので、次に Sematic Kernel 側で C# のソースコードを書いてみました。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Memory.Postgres;
using Microsoft.SemanticKernel.Memory;
using Npgsql;
using Pgvector.Npgsql;
namespace MyOpenAITest
{
class Program
{
public static async Task Main(string[] args) {
// Azure OpenAI parameters
const string deploymentName_chat = "text-davinci-003";
const string endpoint = "https://your-azureopenai-endpoint.openai.azure.com/";
const string openAiKey = "your-azureopenai-key";
const string deploymentName_embedding = "text-embedding-ada-002";
// posgresql connection string
const string connectionString = "Host=your-posgresql-servername.postgres.database.azure.com;Port=5432;Database=your-dbname;User Id=your-usename;Password=your-password";
Console.WriteLine("== Start Applicaiton ==");
NpgsqlDataSourceBuilder dataSourceBuilder = new NpgsqlDataSourceBuilder(connectionString);
dataSourceBuilder.UseVector();
NpgsqlDataSource dataSource = dataSourceBuilder.Build();
PostgresMemoryStore memoryStore = new PostgresMemoryStore(dataSource, vectorSize: 1536/*, schema: "public" */);
IKernel kernel = Kernel.Builder
// .WithLogger(ConsoleLogger.Log)
.WithAzureTextCompletionService(deploymentName_chat, endpoint, openAiKey)
.WithAzureTextEmbeddingGenerationService(deploymentName_embedding, endpoint, openAiKey)
.WithMemoryStorage(memoryStore)
.WithPostgresMemoryStore(dataSource, vectorSize: 1536, schema: "public")
.Build();
string ask = "How can I Associate EA and CSP subscriptions into same AAD tenant?";
Console.WriteLine("===========================\n" +
"Query: " + ask + "\n");
var memories = kernel.Memory.SearchAsync("langchain_pg_collection", ask, limit: 5, minRelevanceScore: 0.77);
int j = 0;
await foreach (MemoryQueryResult memory in memories)
{
Console.WriteLine($"Result {++j}:");
Console.WriteLine(" URL: : " + memory.Metadata.Id);
Console.WriteLine(" Title : " + memory.Metadata.Description);
Console.WriteLine(" Relevance: " + memory.Relevance);
Console.WriteLine();
}
Console.WriteLine("== End Application ==");
}
}
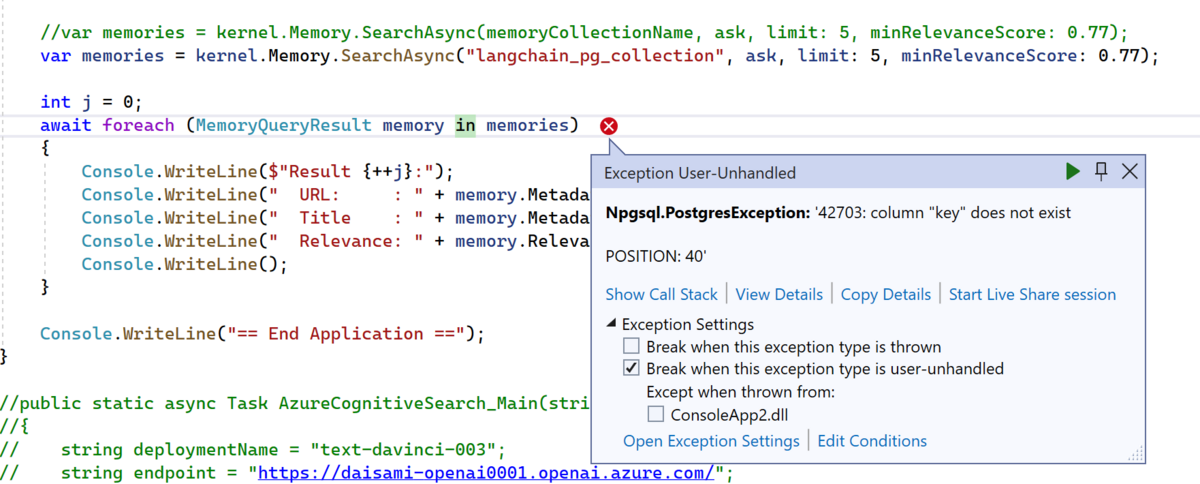
}上記を実行すると以下の様に '42703: column "key" does not exist というエラーが発生します。どうやら key という column が無いようです。
この結果から、Semantic Kernel/C# と LangChain/Python ではベクトルストアへのデータ格納時にスキーマが異なるのではとの推察をしました。
Semantic Kernel/C# 側でベクトルデータを PosgreSQL に格納してスキーマを確認する
次に Semantic Kernel/C# 側でベクトルデータを PosgreSQL に格納してみます。以下の様に GitHub のドキュメント文字列をベクトル化し、ベクトルデータストア(この場合は PosgreSQL)に格納します。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Memory.Postgres;
using Microsoft.SemanticKernel.Memory;
using Npgsql;
using Pgvector.Npgsql;
namespace MyOpenAITest
{
class Program
{
public static async Task Main(string[] args)
{
// Azure OpenAI parameters
const string deploymentName_chat = "text-davinci-003";
const string endpoint = "https://your-azureopenai-endpoint.openai.azure.com/";
const string openAiKey = "your-azureopenai-key";
const string deploymentName_embedding = "text-embedding-ada-002";
// posgresql connection string
const string connectionString = "Host=your-posgresql-endpoint.postgres.database.azure.com;Port=5432;Database=sk_demo;User Id=your-posgresql-username;Password=your-posgresql-password";
Console.WriteLine("== Start Applicaiton ==");
NpgsqlDataSourceBuilder dataSourceBuilder = new NpgsqlDataSourceBuilder(connectionString);
dataSourceBuilder.UseVector();
NpgsqlDataSource dataSource = dataSourceBuilder.Build();
PostgresMemoryStore memoryStore = new PostgresMemoryStore(dataSource, vectorSize: 1536/*, schema: "public" */);
IKernel kernel = Kernel.Builder
// .WithLogger(ConsoleLogger.Log)
.WithAzureTextCompletionService(deploymentName_chat, endpoint, openAiKey)
.WithAzureTextEmbeddingGenerationService(deploymentName_embedding, endpoint, openAiKey)
.WithMemoryStorage(memoryStore)
.WithPostgresMemoryStore(dataSource, vectorSize: 1536, schema: "public")
.Build();
const string memoryCollectionName = "SKGitHub";
var githubFiles = new Dictionary<string, string>()
{
["https://github.com/microsoft/semantic-kernel/blob/main/README.md"]
= "README: Installation, getting started, and how to contribute",
["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/02-running-prompts-from-file.ipynb"]
= "Jupyter notebook describing how to pass prompts from a file to a semantic skill or function",
["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/00-getting-started.ipynb"]
= "Jupyter notebook describing how to get started with the Semantic Kernel",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/skills/ChatSkill/ChatGPT"]
= "Sample demonstrating how to create a chat skill interfacing with ChatGPT",
["https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/SemanticKernel/Memory/Volatile/VolatileMemoryStore.cs"]
= "C# class that defines a volatile embedding store",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/dotnet/KernelHttpServer/README.md"]
= "README: How to set up a Semantic Kernel Service API using Azure Function Runtime v4",
["https://github.com/microsoft/semantic-kernel/tree/main/samples/apps/chat-summary-webapp-react/README.md"]
= "README: README associated with a sample starter react-based chat summary webapp",
};
Console.WriteLine("Adding some GitHub file URLs and their descriptions to a volatile Semantic Memory.");
int i = 0;
foreach (var entry in githubFiles)
{
await kernel.Memory.SaveReferenceAsync(
collection: memoryCollectionName,
description: entry.Value,
text: entry.Value,
externalId: entry.Key,
externalSourceName: "GitHub"
);
Console.WriteLine($" URL {++i} saved");
}
string ask = "How can I Associate EA and CSP subscriptions into same AAD tenant?";
Console.WriteLine("===========================\n" +
"Query: " + ask + "\n");
var memories = kernel.Memory.SearchAsync(memoryCollectionName, ask, limit: 5, minRelevanceScore: 0.77);
//var memories = kernel.Memory.SearchAsync("langchain_pg_collection", ask, limit: 5, minRelevanceScore: 0.77);
int j = 0;
await foreach (MemoryQueryResult memory in memories)
{
Console.WriteLine($"Result {++j}:");
Console.WriteLine(" URL: : " + memory.Metadata.Id);
Console.WriteLine(" Title : " + memory.Metadata.Description);
Console.WriteLine(" Relevance: " + memory.Relevance);
Console.WriteLine();
}
Console.WriteLine("== End Application ==");
}
}
}上記を実行後、PosgreSQL に接続した結果、スキーマは以下の様になりました。御覧の通り、Semantic Kernel 側で作成したスキーマには text 型のデータを格納する key という名前のカラムが存在しますが、LangChain 側には存在しないカラムなことが分かります。

そのほかにも、embedding されたデータを格納するカラムのデータ型・カラム名は同じなことは分かりますが、その他は異なるカラムでのデータが格納されていることが分かると思います。
「Semantic Kernel/C# をフロントエンド、LangChain/Python をバックエンドとして Azure OpenAI を使えるか?」の結論
本ポストの掲題でもあったテーマについては、実現は難しいというのが結論になると思います。両ライブラリで格納されたベクトルデータだけは同じですが、他のカラム等々は異なるデータ形式で格納されているので、現実的にはこちらを上手くマッピングさせて相互運用というのは難しいのではと考えています。
上記に加え、「既に PosgreSQL に格納されているベクトル化データをそのまま別のデータストア(Azure Cognitive Search 等)に移行したい」というベクトルデータの格納コンポーネントを変えるという処理も、今回の結果を踏まえれば難しいという推察ができます。データのマッピングを考えるより、新しくベクトル化データを作り直す方が現実的でしょう。
結果的に期待を満たすのでなく、実現が難しいという知見を得るにとどまってしまいましたが、こちらの検証結果が皆様のお役に立てば幸いです。
Azure OpenAI でトークン制限に引っかかった時に発生する例外
ご存じの通り、Azure OpenAI は非常に需要が高いサービスですが、その要求にこたえる必要もあり、一分辺りに利用できるトークン数が決まっています。以下のサイトにはそちらの詳細が記載されています。
learn.microsoft.com
Azure OpenAI の Tokens per Minute Rate Limit は以下の様に、特定のデプロイメントに対しての割り当てが可能であり、モデル&リージョン&サブスクリプション単位で上限が割り振られます。
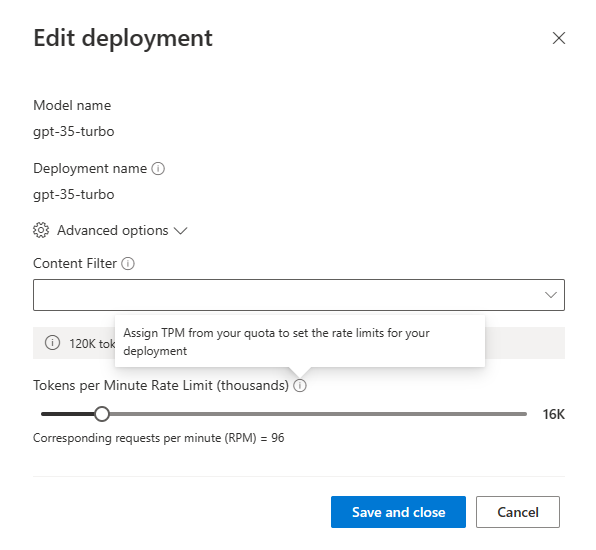
上記の様に各デプロイメントに対して上限割り振りが可能ですが、以下のような状況になります。
- 例:Japan East に gpt-35-turbo モデルの MRL を deployment-01 に 120k 割り振った場合
- UK South 等の他のリージョンは deployment-01 の影響を受けず、gpt-35-turbo モデルの新規デプロイメントに MRL を割り当て可
- Japan East に gpt-35-turbo モデルを使った新規デプロイメントdeployment-02 を作成する場合、MRL は何も割り当てられない
つまり Azure OpenAI の Tokens per Minute Rate Limit 上限を回避するには「①リージョンを分ける」か「②サブスクリプションを分ける」かのどちらか(または両方)を行う必要があるというのが現状です。その場合、「プログラム側にどのようなエラーメッセージが返ってくるのか?」が振り分け時のキモになると考えています。以前に作成した Java では以下の様なエラーが返ってきました。
at xyz.normalian.example.ChatCompletionApplication.main(ChatCompletionApplication.java:100)
Exception in thread "main" org.springframework.web.client.HttpClientErrorException$TooManyRequests: 429 Too Many Requests: "{"error":{"code":"429","message": "Requests to the Creates a completion for the chat message Operation under Azure OpenAI API version 2023-03-15-preview have exceeded call rate limit of your current OpenAI S0 pricing tier. Please retry after 8 seconds. Please go here: https://aka.ms/oai/quotaincrease if you would like to further increase the default rate limit."}}"エラーメッセージには Token 上限に引っかかった旨、何秒後にリトライしたら良いかが記載されているのが分かると思います。また、以下のサイトでの Quota を増やす申請も可能です。
https://aka.ms/oai/quotaincrease
こちらが参考になれば幸いです。
Semantic Kernel を利用して PosgreSQL を利用してベクトル検索をしてみる
今回は掲題通り、Semanic Kernel を利用して PosgreSQL をベクトルストアとして利用してみたいと思います。前回のポストでは Azure Cognitive Search をベクトルストアとして利用しようと試みましたが、connecter の成熟度が現時点(2023年7月7日現在)はイマイチなこともあり、こちらの活用は難しい状況でした。
normalian.hatenablog.com
こちらに対して、現時点で Azure 上でベクトルストアとして利用できる組み込みサービスは現時点では以下となる認識です。
- Azure Cosmos DB for MongoDB cluster
- public preview
- EastUS, West Europe, Australia East
- Azure Cognitive Search
- private preview
- 7月9日追記:public preview になった模様 Vector search - Azure Cognitive Search | Microsoft Learn
- Japan East/Japan West で利用可能
- Azure Redis
- Azure Database for PostgreSQL - フレキシブル サーバ
日本で利用することを考える場合、Azure Database for PostgreSQL - フレキシブル サーバが良さそうな感じがしています。そこで今回は Semantic Kernel を利用して Azure Database for PostgreSQL をベクトルデータストアとして活用します。
Azure Database for PostgreSQL - フレキシブル サーバ の作成と設定
Azure Portal 上からリソースを作成します。以下の様に似たリソースがいくつかありますが、Azure Database for PosgreSQL flexible servers を選択します。

リソース作成後、ポータル上より以下の様に Server parameters のメニュー内にある azure.extensions から VECTOR を有効化しました。

しかし、後で紹介するソースコード実行時に機能が有効化されていない状態でした。もし同様の現象が発生した場合、以下の様にコマンドを実行して有効化しましょう。
daisami@mysurfacebook1:~$ psql -h your-server-name.postgres.database.azure.com -p 5432 -U myadminuser sk_demo
Password for user myadminuser:
psql (12.15 (Ubuntu 12.15-0ubuntu0.20.04.1), server 14.7)
WARNING: psql major version 12, server major version 14.
Some psql features might not work.
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
sk_demo=> CREATE EXTENSION IF NOT EXISTS "vector";
NOTICE: extension "vector" already exists, skipping
CREATE EXTENSION
sk_demo=> CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
NOTICE: extension "uuid-ossp" already exists, skipping
CREATE EXTENSION
sk_demo=>これで PosgreSQL でベクトル化データを保存できるようになりました。こちらはてらだよしおさんの以下の記事を参考にしています。
qiita.com
C# の Semantic Kernel を利用してPosgreSQL にベクトル化データを保存する
こちらに関してはほぼ以下のサンプルコードからのぱくりとなりますが、PosgreSQL との組み合わせが分からない人が多いと思いますので参考の為にアレコレ書いておきます。
learn.microsoft.com
まず、C#のプロジェクトを作成し、以下の様に Microsoft.SemanticKernel と Microsoft.SemanticKernel.Connectors.Memory.Postgres を nuget を使って読み込みましょう。

次に以下のソースコードを実行します。
using Microsoft.SemanticKernel; using Microsoft.SemanticKernel.Connectors.Memory.Postgres; using Microsoft.SemanticKernel.Memory; using Npgsql; using Pgvector.Npgsql; namespace MyOpenAITest { class Program { public static async Task Main(string[] args) { // Azure OpenAI parameters const string deploymentName_chat = "text-davinci-003"; const string endpoint = "https://your-endpoint.openai.azure.com/"; const string openAiKey = "open-ai-key"; const string deploymentName_embedding = "text-embedding-ada-002"; // posgresql connection string const string connectionString = "Host=your-server-name.postgres.database.azure.com;Port=5432;Database=sk_demo;User Id=your-username;Password=your-password"; Console.WriteLine("== Start Applicaiton =="); NpgsqlDataSourceBuilder dataSourceBuilder = new NpgsqlDataSourceBuilder(connectionString); dataSourceBuilder.UseVector(); NpgsqlDataSource dataSource = dataSourceBuilder.Build(); PostgresMemoryStore memoryStore = new PostgresMemoryStore(dataSource, vectorSize: 1536/*, schema: "public" */); IKernel kernel = Kernel.Builder // .WithLogger(ConsoleLogger.Log) .WithAzureTextCompletionService(deploymentName_chat, endpoint, openAiKey) .WithAzureTextEmbeddingGenerationService(deploymentName_embedding, endpoint, openAiKey) .WithMemoryStorage(memoryStore) .WithPostgresMemoryStore(dataSource, vectorSize: 1536, schema: "public") .Build(); const string memoryCollectionName = "SKGitHub"; var githubFiles = new Dictionary<string, string>() { ["https://github.com/microsoft/semantic-kernel/blob/main/README.md"] = "README: Installation, getting started, and how to contribute", ["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/02-running-prompts-from-file.ipynb"] = "Jupyter notebook describing how to pass prompts from a file to a semantic skill or function", ["https://github.com/microsoft/semantic-kernel/blob/main/samples/notebooks/dotnet/00-getting-started.ipynb"] = "Jupyter notebook describing how to get started with the Semantic Kernel", ["https://github.com/microsoft/semantic-kernel/tree/main/samples/skills/ChatSkill/ChatGPT"] = "Sample demonstrating how to create a chat skill interfacing with ChatGPT", ["https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/SemanticKernel/Memory/Volatile/VolatileMemoryStore.cs"] = "C# class that defines a volatile embedding store", ["https://github.com/microsoft/semantic-kernel/tree/main/samples/dotnet/KernelHttpServer/README.md"] = "README: How to set up a Semantic Kernel Service API using Azure Function Runtime v4", ["https://github.com/microsoft/semantic-kernel/tree/main/samples/apps/chat-summary-webapp-react/README.md"] = "README: README associated with a sample starter react-based chat summary webapp", }; Console.WriteLine("Adding some GitHub file URLs and their descriptions to a volatile Semantic Memory."); int i = 0; foreach (var entry in githubFiles) { await kernel.Memory.SaveReferenceAsync( collection: memoryCollectionName, description: entry.Value, text: entry.Value, externalId: entry.Key, externalSourceName: "GitHub" ); Console.WriteLine($" URL {++i} saved"); } string ask = "I love Jupyter notebooks, how should I get started?"; Console.WriteLine("===========================\n" + "Query: " + ask + "\n"); var memories = kernel.Memory.SearchAsync(memoryCollectionName, ask, limit: 5, minRelevanceScore: 0.77); int j = 0; await foreach (MemoryQueryResult memory in memories) { Console.WriteLine($"Result {++j}:"); Console.WriteLine(" URL: : " + memory.Metadata.Id); Console.WriteLine(" Title : " + memory.Metadata.Description); Console.WriteLine(" Relevance: " + memory.Relevance); Console.WriteLine(); } Console.WriteLine("== End Application =="); } } }
上記を実行すると以下の結果となります。

こちらはインターネット上から直接テキストを読み取っているだけなので、こちらを PDF やオフィスファイル等と組み合わせればアレコレできると思います。
Semantic Kernel を利用して Azure Cognitive Search のインデックスにベクトル検索してみる(失敗編)
以前に Azure Cognitive Search がベクトル検索に対応した件、python でベクトル検索を実施した件をそれぞれ試しました。
normalian.hatenablog.com
normalian.hatenablog.com
Azure OpenAI とベクトル検索を組み合わせてどの様に動くかはご理解いただけたと思いますが、これらはどちらも Python コードで実行されており、C# 等になじみのある方々にとって自身のアプリに組み込むのは少しハードルがある状況だと思います。
こちらに対して、Python 側で主要なライブラリである LangChain 相当のことを目指す Sentiment Kernel と呼ばれるライブラリが既に発表されており、既に Azure Cognitive Search 向けのコネクタも提供されていることが分かりました。
github.com
今回は実際にソースコードを書いて&実行して Azure Cognitive Search のインデックスにベクトル検索をしてみました。が、結果から言うと「Semantic Kernel の Azure Cognitive Search 向け Connector がベクトル検索に対応していない」という理由で失敗しました(あくまで2023年7月7日現在の話)。ここまでアレコレしたので、せっかくなので途中経過だろうがまとめようと思ったのが今回の記事になります
Semantic Kernel で Azure Cognitive Search を利用する
Semantic Kernel で Azure Cognitive Search を利用する場合は以下の様に Microsoft.SemanticKernel と Microsoft.SemanticKernel.Connectors.Memory.AzureCognitiveSearch のライブラリを nuget 経由でインストールする必要があります。
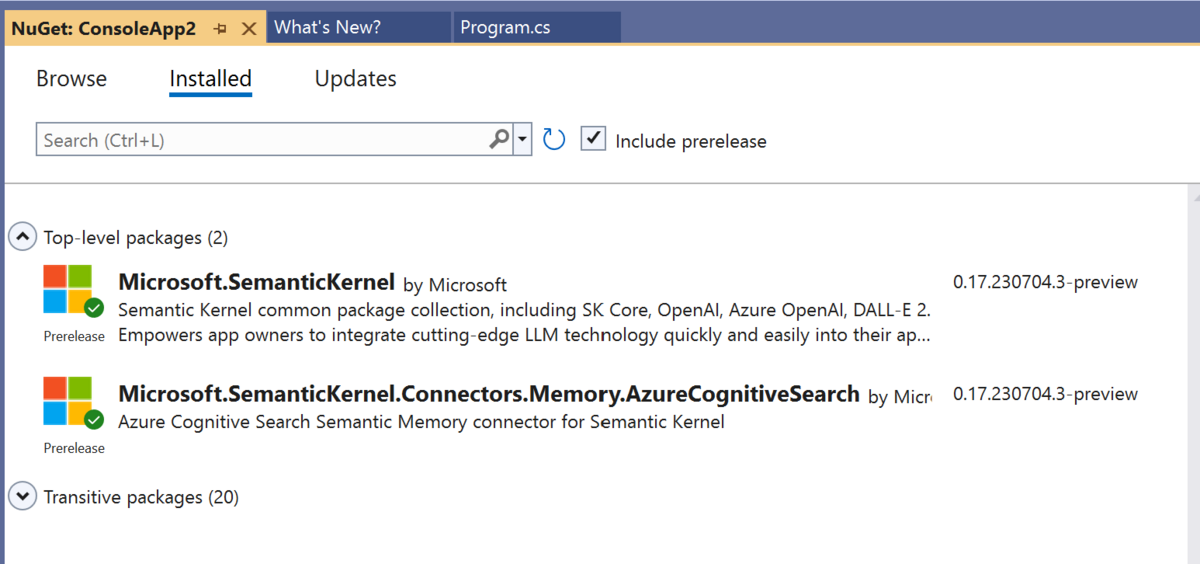
この際に include prerelease にチェックを入れるのを忘れないようにしましょう。
以下が実際に利用したコードですが、実行前に Azure Cognitive Search のインデックス側にデータを格納する必要があります。Azure Cognitive Search という「ベクトル化データのデータストア」にどの様にデータを格納するかは Azure OpenAI での Embedding 時にパラメータ弄って観察する - normalian blog を参照ください。
using Microsoft.SemanticKernel;
namespace MyOpenAITest
{
class Program
{
public static async Task Main(string[] args)
{
string deploymentName = "text-davinci-003";
string endpoint = "https://xxxxxxxxxxxxxx.openai.azure.com/";
string openAiKey = "your-openai-key";
string deploymentName_embedding = "text-embedding-ada-002";
string azuresearchEndpoint = "https://xxxxxxxxxxxxx-koreasouth.search.windows.net";
string azuresearchKey = "your-azuresearch-key";
string azuresearchIndexname = "your-index-name";
Console.WriteLine("== Start Applicaiton ==");
var builder = new KernelBuilder();
builder.WithAzureTextCompletionService(
deploymentName, // Azure OpenAI Deployment Name
endpoint, // Azure OpenAI Endpoint
openAiKey);
IKernel kernel = Kernel.Builder
.WithOpenAITextCompletionService(deploymentName, openAiKey)
.WithOpenAITextEmbeddingGenerationService(deploymentName_embedding, openAiKey)
.WithAzureCognitiveSearchMemory(
azuresearchEndpoint,
azuresearchKey)
.Build();
var searchResult = kernel.Memory.SearchAsync(azuresearchIndexname,
"Please let me know Azure subscription structure");
await foreach (var result in searchResult)
{
Console.Write($"id ={result.Metadata.Id}, text={result.Metadata.Text}");
}
Console.WriteLine("== End Application ==");
}
}
}こちらを実行すると残念ながら以下の結果が返ってきます。値の中身が全く入っていません。
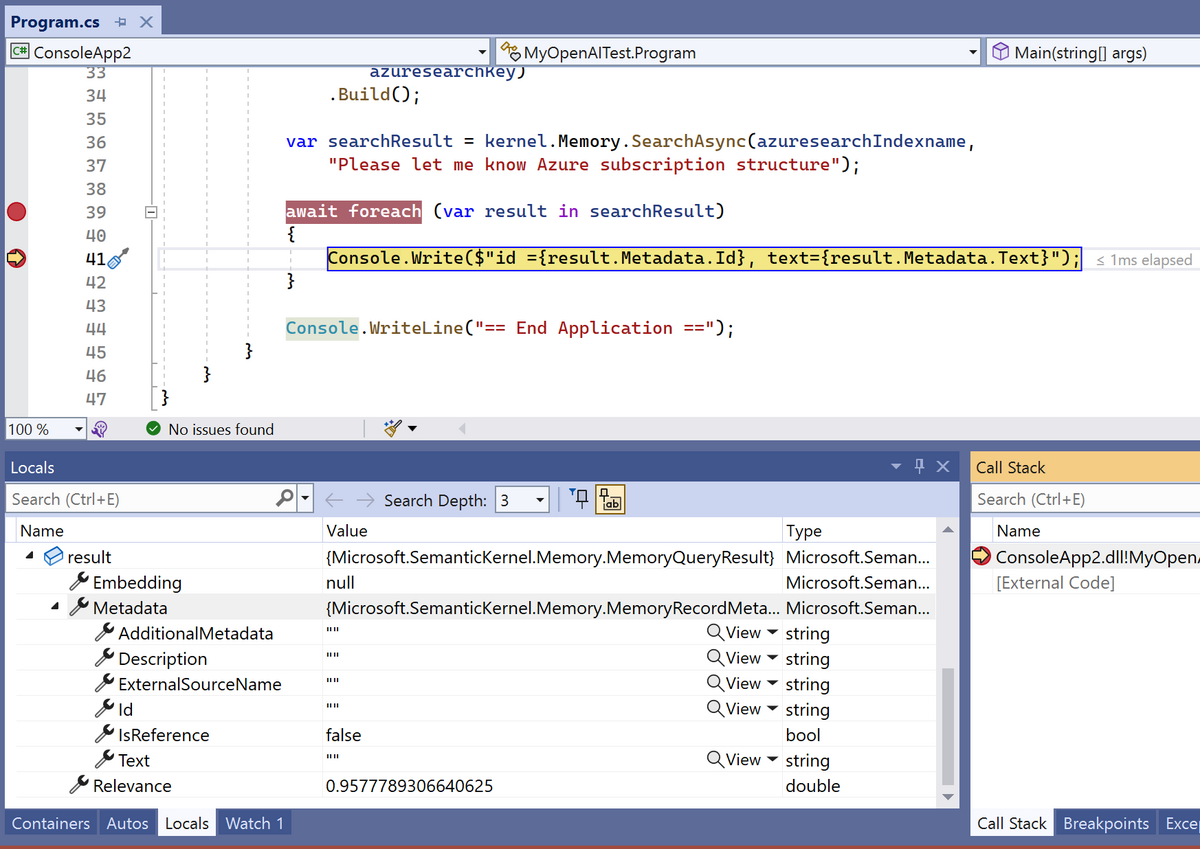
なんで検索が上手くいかないの?
その答えは Semantic Kernel のソースコード自体を読み込むことで理解ができました。以下を参照ください。
github.com
以下のソースコード周辺で "// TODO: use vectors" という記載があり、今の時点ではベクトル検索にライブラリ自体が対応していないことが見受けられます(これは多少弄った程度だとどうにもならなそうでした)。
ハマったところ① - Semantic 検索がオフにできない
最初に出くわしたエラーは以下の「Semantic 検索を有効にしてないぞ」です。
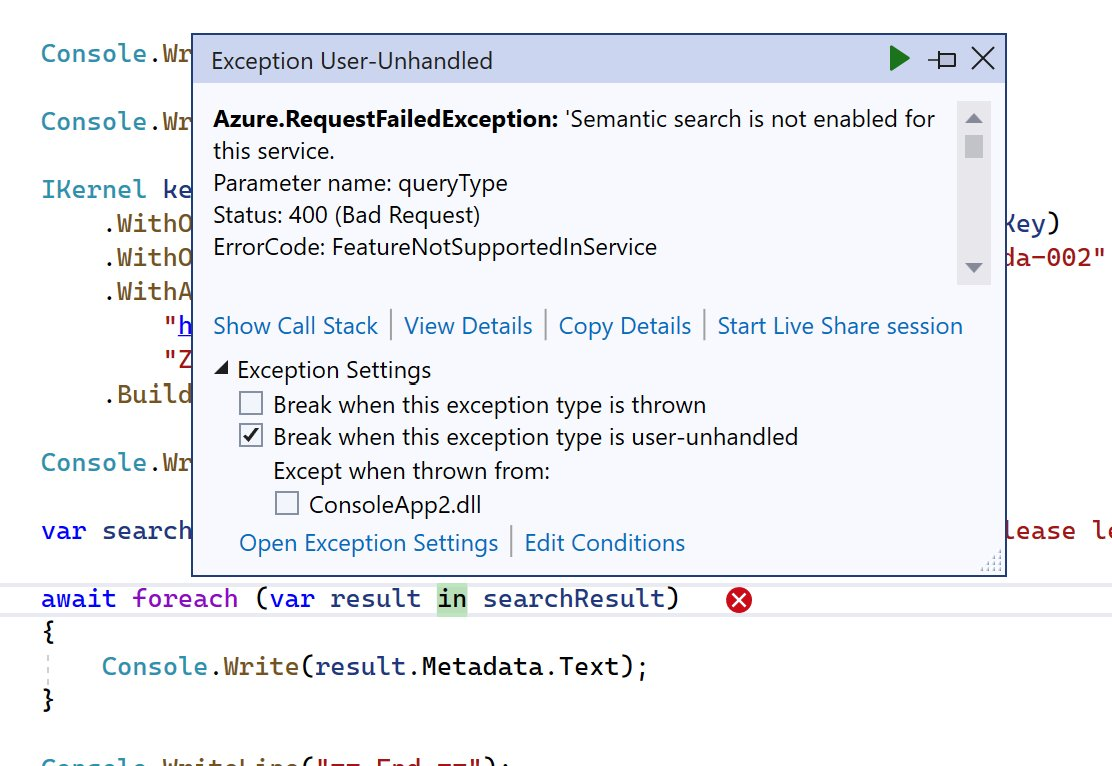
こちらは困った問題で、現時点(2023年7月7日現在)では Japan East/Japan West ともに Azure Cognitive Search は Semantic 検索 に対応しておりません。
azure.microsoft.com
仕方ないので Korea South で Azure Cognitive Search のリソースを作り直して回避しました。
Korea South リージョンで Azure Cognitive Search のリソースを作ると以下の様に左側のメニューに「Semantic Search (preview)」が表示されるので、ここで有効化します。
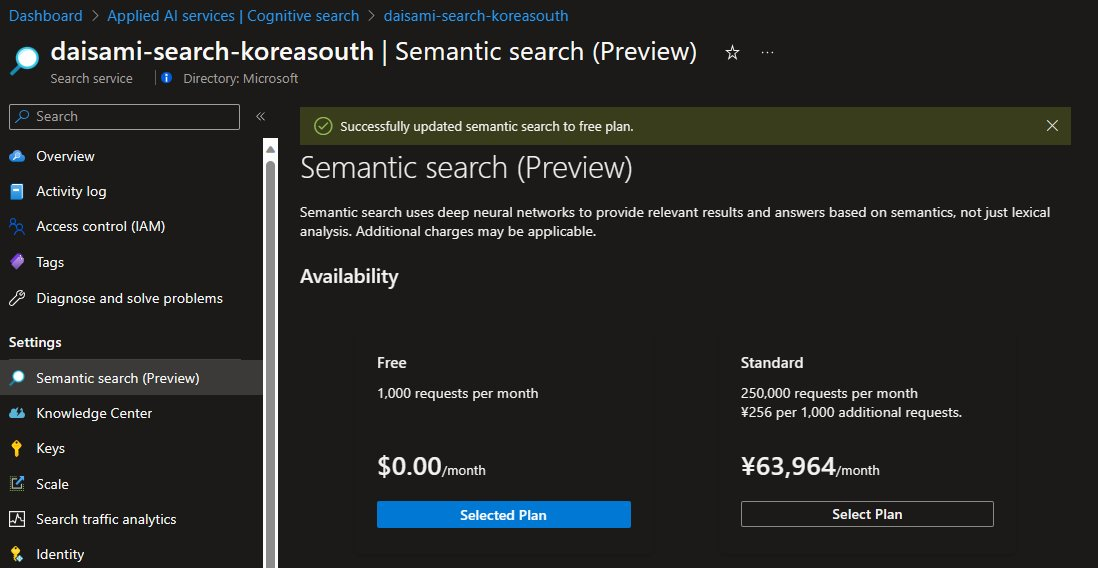
ハマったところ② - Semantic 検索用の設定を作る
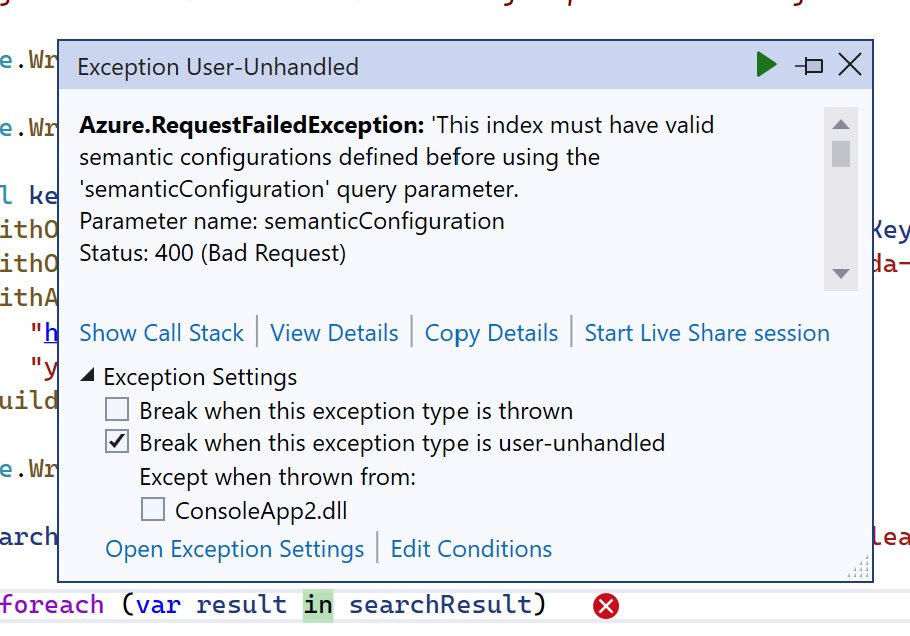
Azure Cognitive Search のインデックスにて Semantic 検索用の設定をしない場合、今度は以下のエラーが発生します。
こちらに関しては以下の様にポータル側で設定しようとしたのですが、何故か Save リンク(ボタン?)が有効にならずにうまくいきませんでした。
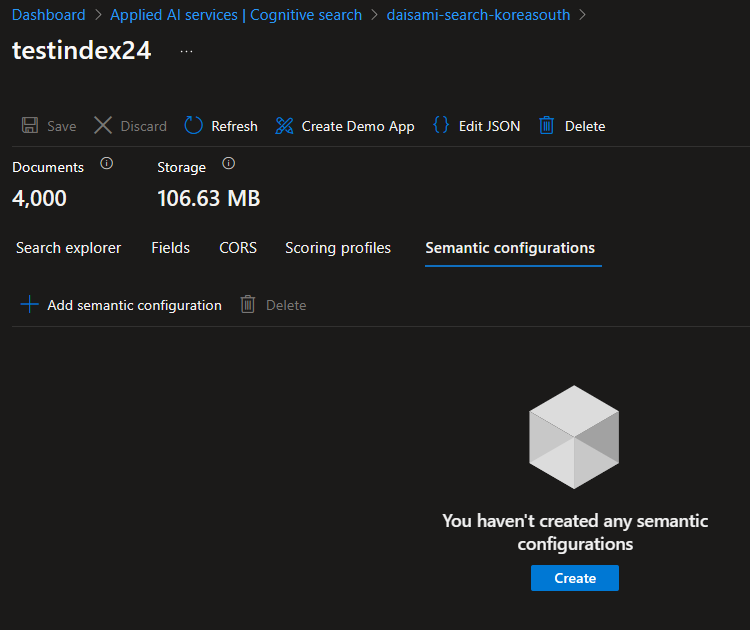
仕方がないので上記スクリーンショットでの "Edit JSON" リンクを押下し、以下の設定を追記しました。
"semantic": { "configurations": [ { "name": "default", "prioritizedFields": { "titleField": { "fieldName": "title" }, "prioritizedContentFields": [ { "fieldName": "content" } ], "prioritizedKeywordsFields": [ { "fieldName": "tag" } ] } } ] }
加えて、この設定名は必ず default にする必要があります。間違えると以下のエラーが発生します。
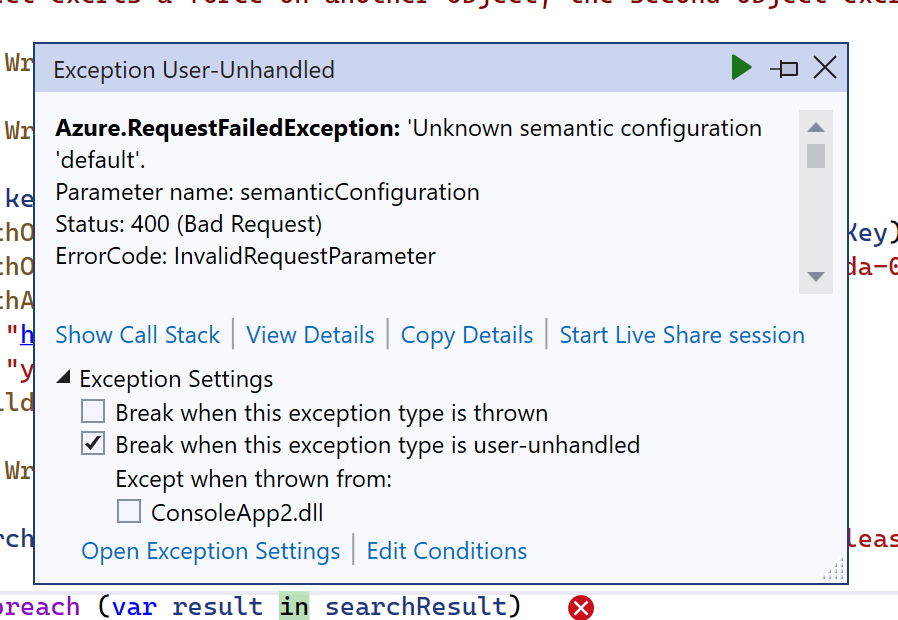
そこについては以下のソースコードを参照すると分かりますが、直接ハードコードされています。
github.com
結論
あくまで2023年7月7日現在となりますが、Azure Cognitive Search に対しては Semantic Kernel はまだ未成熟なようです。その一方で別のベクトル化データのストアは当然あるので、そういったものをアレコレ調べるのも面白そうです。
Azure OpenAI での Embedding 時にパラメータ弄って観察する
前回は Azure Cognitive Search のベクトル検索で hello world をしてみましたが、あの程度で「これで現場で使えるな」と満足してくれる人は居ないでしょう。以下の記事ではどの様に使うかまでは踏み込みましたが、特にパラメータ設定もしてないこともあり、あまり期待する結果が得られなかったというのが現実でした。
normalian.hatenablog.com
今回は一部のパラメータを弄ってもう少し期待した結果を返してもらいたいと思います。今回は以下の部分の chunk_size と chunk_overlap に注目したいと思います。同記事はテキストデータを Azure OpenAI でEmbedding する前、テキストを一定のまとまり( chunk )にするコード片です。全体のコードを見たい方は前回の記事を参照ください。
source_url = 'https://your-storage-account-name.blob.core.windows.net/xxxxxxx/xxxxxxxxxx.pdf' chunk_size = 500 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents)
chunk_size と chunk_overlap って何?
ここが分からないとパラメータを変更をしても何が何やら分からなくなってしまうので、まずこのパラメータが何をしているかを確認しましょう。そのためには以下の記事が参考になります。そこには「TokenTextSplitter splits a raw text string by first converting the text into BPE tokens」という記載があり、BPE トークンと呼ばれるものに文字列を変換する模様です。
js.langchain.com
では BPE トークンが何かというと今度は以下の記事が参考になり、BPE は Bite Pair Encoding の略であり、頻出する文字列の組み合わせからその分割方法を学習するものだそうです。
cardinal-moon.hatenablog.com
そろそろ用語のキャッチアップばかりで疲れてきたと思いますので、以下のコードで実際に確かめてみましょう。サンプル文字列に対して chunk_size と chunk_overlap を設定しています。
from langchain.text_splitter import TokenTextSplitter, TextSplitter
text = "I often hear opinions similar to 'Is there any innovative business that offers high profits without risks?', but it sounds like same opinion with high school girls who want to lose weight but still crave sweet treats."
chunk_size = 10
chunk_overlap = 3
text_splitter: TextSplitter = TokenTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
encoding_name="gpt2")
output = text_splitter.create_documents([text])
print(output)こちらの結果は以下の様になります。実際には一行で出ていますが、読みやすい様に改行しているのでご注意ください。
PS C:\opt\workspace\Test-VectorSearch> python .\test_splitter.py
[Document(page_content="I often hear opinions similar to 'Is there any", metadata={}),
Document(page_content='Is there any innovative business that offers high profits without', metadata={}),
Document(page_content=" high profits without risks?', but it sounds like", metadata={}),
Document(page_content=' it sounds like same opinion with high school girls who', metadata={}),
Document(page_content=' school girls who want to lose weight but still crave', metadata={}),
Document(page_content=' but still crave sweet treats.', metadata={})]
PS C:\opt\workspace\Test-VectorSearch> 上記を見て頂ければ分かると思いますが、設定した chunk_size(=10 単語)以下でひとまとまりにされ、設定した chunk_overlap(= 3 単語)で前後の chunk と重複していることが分かります。
では日本語ではどうなるのでしょうか?殆どの読者各位は日本語での内容が気になると思いますので、当該英文を日本語に直して試してみたいと思います。実行したのは以下のコードで内容は変えていません。
from langchain.text_splitter import TokenTextSplitter, TextSplitter
text = "「リスクなしに高収益が得られる革新的なビジネスはないのか」というような意見をよく耳にするが、「痩せたいけど甘いものが食べたい」という女子高生と同じ意見に聞こえる。"
chunk_size = 10
chunk_overlap = 3
text_splitter: TextSplitter = TokenTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
encoding_name="gpt2")
output = text_splitter.create_documents([text])
print(output)実行結果は以下になります。こちらも実際には一行で出ていますが、読みやすい様に改行しているのでご注意ください。
PS C:\opt\workspace\Test-VectorSearch> python .\test_splitter.py
[Document(page_content='「リスクなしに高�', metadata={}),
Document(page_content='高収益が得ら', metadata={}),
Document(page_content='得られる革新', metadata={}),
Document(page_content='�新的なビジネスは', metadata={}),
Document(page_content='ネスはないのか」とい', metadata={}),
Document(page_content='」というような意', metadata={}),
Document(page_content='な意見をよく�', metadata={}),
Document(page_content='�く耳にするが、「', metadata={}),
Document(page_content='が、「痩せたい', metadata={}),
Document(page_content='�たいけど甘い', metadata={}),
Document(page_content='甘いものが食べ', metadata={}),
Document(page_content='�べたい」という女', metadata={}),
Document(page_content='いう女子高生と同', metadata={}),
Document(page_content='と同じ意見に', metadata={}),
Document(page_content='見に聞こえる', metadata={}),
Document(page_content='える。', metadata={})]御覧の通り、日本語の方が分割数が多いのが確認できると思います。英語や多くのヨーロピアン言語と異なり、日本語を含むアジア圏の国は「スペースで単語を区切る」という言語構造をしていないこともあり、こうした分割時には言語固有の癖が出ているのが確認できます。設定した chunk_size や chunk_overlap からするとやや文字数が少ない様に見受けられるのですが、単にマルチバイト文字だからなのかこの辺りはもしわかる方がコメント頂ければ幸いです。
chunk_size を変えて試してみる
では次に実際のデータを食わせて考えてみましょう今回は以下のPDF ファイル(に似たものを厳密には利用しています) を試したいと思います。ずいぶん前になりますが、Azure における EA と CSP における subscription 管理についてまとめた資料になります。こちらは EA や CSP とは何か?に加え、Microsoft アカウントと組織アカウントについて、一つの Azure AD テナントに複数の EA/CSP subscription がつけられるか等がまとまっています。
それぞれ以下のパラメータで Azure Cognitive Search 上でインデックスを作成してみました。
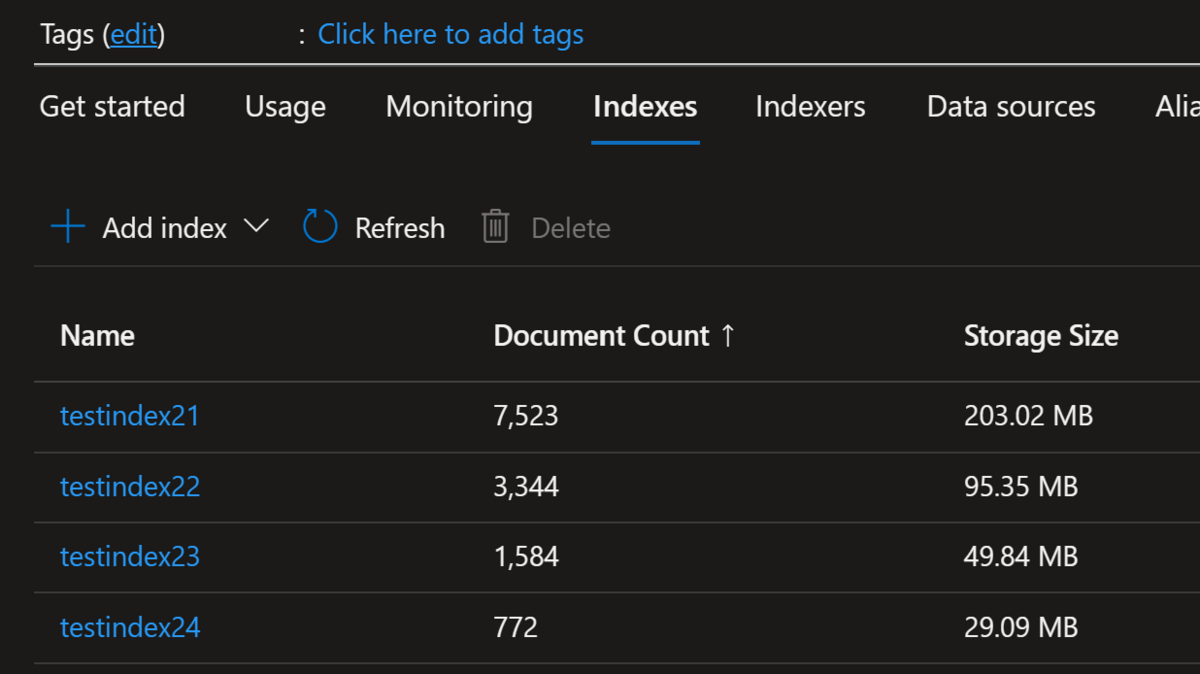
- testindex21: chunk_size = 500, chunk_overlap = 100 のケース
- testindex22: chunk_size = 1000, chunk_overlap = 100 のケース
- testindex23: chunk_size = 2000, chunk_overlap = 100 のケース
- testindex24: chunk_size = 4000, chunk_overlap = 100 のケース
数字を見ればご認識頂けると思いますが、chunk_size を大きくした分だけまとまりが大きくなっているので、その分だけ Azure Cognitive Search のドキュメント数が少なくなり、加えて冗長分が減っただけデータサイズも小さくなっています。
次に実際にクエリを発行してみましょう。抜粋するとコード片は以下です(※全体を見たい場合は前回の記事を参照下さい)。
index_name ='testindex21' # 'testindex22', 'testindex23', 'testindex24' question = 'What is best practice to leverage both EA and CSP for a customer?' prompt = PROMPT chat_history = [] (中略) question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT, verbose=False) doc_chain = load_qa_with_sources_chain(llm, chain_type="stuff", verbose=True, prompt=prompt) chain = ConversationalRetrievalChain( retriever=vector_store.as_retriever(), question_generator=question_generator, combine_docs_chain=doc_chain, return_source_documents=True, max_tokens_limit=7000 ) result = chain({"question": question, "chat_history": chat_history}) context = "\n".join(list(map(lambda x: x.page_content, result['source_documents']))) sources = "\n".join(set(map(lambda x: x.metadata["source"], result['source_documents']))) result['answer'] = result['answer'].split('SOURCES:')[0].split('Sources:')[0].split('SOURCE:')[0].split('Source:')[0] print('#### source ') print(sources) print('#### question ') print(question) print('#### answer ') print(result['answer'])
各処理結果を見てみましょう。
testindex21: chunk_size = 500, chunk_overlap = 100 のケース
index_name ='testindex21' #### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to associate their EA and CSP subscriptions into the same AAD tenant and perform a migration assessment for using Azure resources. (Slide 42)
御覧の様にかなり簡潔な答えが返ってきます。スライド番号まで示してくれているので確認したところ、以下のスライドなのでかなりいい線に行っている気がしますが、別に migration assessment は必須ではないのでどこかで意味が混じっている気がします。
testindex22: chunk_size = 1000, chunk_overlap = 100 のケース
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to associate EA and CSP subscriptions into the same AAD tenant and perform a migration assessment for using Azure resources. (Slide 42)
こちらは殆ど結果は一緒です。やや文言は異なりますが、同じ内容が帰ってきていると言い切って問題ないでしょう。
testindex23: chunk_size = 2000, chunk_overlap = 100 のケース
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to use EA for centralized management and governance of Azure subscriptions, and CSP for flexible and scalable purchasing and support options for individual customers. (
こちらの結果では CSP の説明に重きを置いた結果が返ってきていますが、参照スライド番号が消えてしまっています。こちらはちょっとイマイチな結果になっていると言っていいでしょう。
testindex24: chunk_size = 4000, chunk_overlap = 100 のケース
resp, got_stream = self._interpret_response(result, stream)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\daisami\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\openai\api_requestor.py", line 624, in _interpret_response
self._interpret_response_line(
File "C:\Users\daisami\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\openai\api_requestor.py", line 687, in _interpret_response_line
raise self.handle_error_response(
openai.error.InvalidRequestError: This model's maximum context length is 8192 tokens. However, your messages resulted in 16409 tokens. Please reduce the length of the messages.こちらではエラーとなってしまいました。どうやらモデルの context length を超えてしまったようです。エラー回避のために以下の様にコードを変更しました。
chain = ConversationalRetrievalChain(
retriever=vector_store.as_retriever(),
question_generator=question_generator,
combine_docs_chain=doc_chain,
return_source_documents=True,
max_tokens_limit=7000
)
結果で帰ってきた内容は以下となります。
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to use the EA for centralized billing and management of large-scale workloads, and CSP for agile and flexible management of smaller workloads. (
三つ目のケースと似たような内容が帰ってきています。
結果
御覧の様に chunk サイズを伸ばしても結果が洗練されるわけではないということが分かりました。今回は英語で chunk_size を 500 としましたが、英語では500単語という意味なるので、最初からやや大き目な chunk_size だったのかなと思います。
日本語で実施した場合は chunk_size は大き目にしないと文脈を失う可能性がありそうですが、chunk_size を大きくしすぎると token 数の制限に引っかかってしまう点にも注意です。
Azure Cognitive Search のベクトル検索機能で helloworld
2023 年 5 月に実施された Microsoft Build というイベントで Azure Cognitive Search にベクトル検索機能が private preview で追加されました。同機能単体で見ると「?」な人も居ると思いますが、Azure OpenAI と組みあわせることで強力な力を発揮します。この辺りの詳細については以下の Qiita 記事が非常に良くまとまっています。
qiita.com
qiita.com
OpenAI 単体でも様々なことが実現可能ですが、社畜業を営む我々としては「俺たちの内部データを使ってもっと OpenAI の回答をカスタマイズできないのか?ただし閉域網でな!!」という「ダイエットしたいけど甘いものが食べたい」的なことがが気になって仕方がないことでしょう。閉域網に関しては単に private endpoint 等の Azure VNET の機能を活用すれば何とかなるので割愛しますが、元々要件を達成するにはテキストの 埋め込み が非常に重要になります。Azure OpenAI では Embeddings API を利用し、テキストをベクトル化することでテキスト間の類似性をコサイン類似度と呼ばれる尺度ではかることができます。
そもそも Azure Cognitive Search のベクトル検索機能って今使えるの?
Microsoft Build 2023 で発表された機能ですが、2023 年 6 月 19 日現在では private preview 機能となりますがリージョン指定は特にないので、日本のリージョン(東日本は試しました)で利用可能です。現在は以下のフォームを埋めて private preview に参加依頼を出す必要があります。
https://aka.ms/VectorSearchSignUp
フォームを埋めたりというと心理障壁があると思いますが、フォームを埋めた数十分くらいで以下のメールが来てあっという間に機能が有効化されたので、使いたかったらとりあえず試してみるのはお勧めです。
PDF データをベクトル化して Azure Search のインデックスに保存してみる
参考にしたサンプルは以下のサンプルとなります。
github.com
特に以下の Azure Cognitive Search に関する helper クラスに関してはそのまま流用しました。
azure-open-ai-embeddings-qna/code/utilities/azuresearch.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
ベクトル検索の設定に関しては特に以下の行周辺が参考になります。
https://github.com/Azure-Samples/azure-open-ai-embeddings-qna/blob/main/code/utilities/azuresearch.py#L83
現時点で Azure Portal 上ではベクトル検索のフィールドは作成することはできませんが、上記の python スクリプトを用いてインデックスを作成すると Azure Portal では以下の様に表示されます。
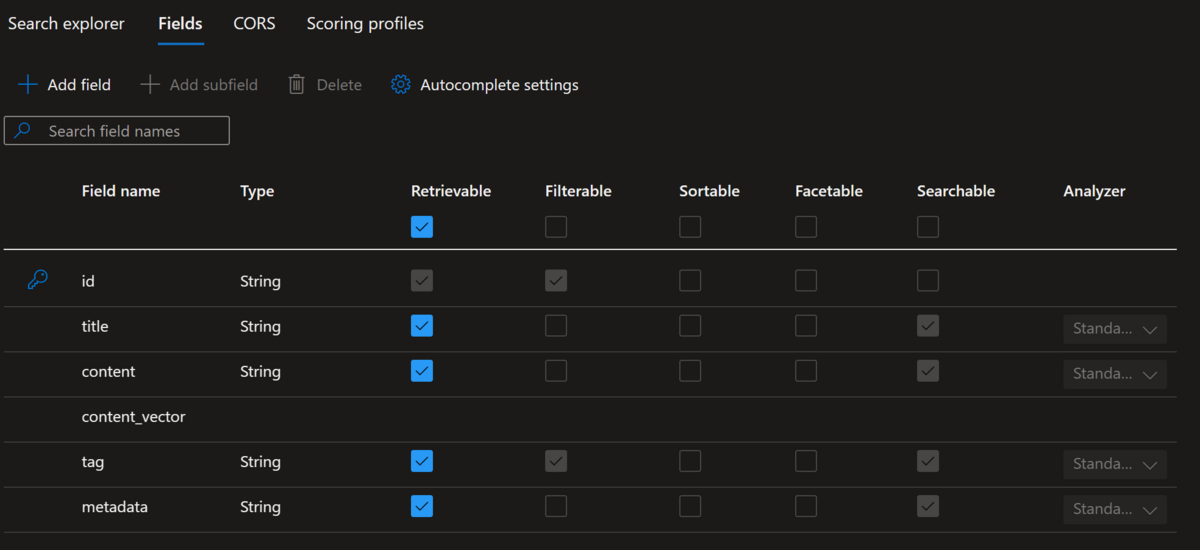
では実際に pptx ファイルを pdf ファイルとして Azure Blob Storage に保管し、Azure OpenAI では Embeddings API を利用してテキストをベクトル化し、Azure Cognitive Search のインデックスに保存します。上記の通り Azure Cognitive Search に関する helper クラスを丸々流用しているので、以下を実際に動かす際はそちらも確認下さい。
from azuresearch import AzureSearch from langchain.embeddings.openai import OpenAIEmbeddings from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import TokenTextSplitter, TextSplitter import hashlib deployment="text-embedding-ada-002" # put your deployment name chunk_size=1 openai_api_type="azure" openai_api_key="put your Azure OpenAI key" openai_api_base="put your Azure OpenAI endpoint - https://your-azureopenai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" vector_store_address ='https://your-search-account-name.search.windows.net' vector_store_password = 'put your search account key' index_name ='put your index name' embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) vector_store = AzureSearch(azure_cognitive_search_name=vector_store_address, azure_cognitive_search_key=vector_store_password, index_name=index_name, embedding_function=embeddings.embed_query) source_url = 'https://your-storage-account-name.blob.core.windows.net/xxxxxxx/xxxxxxxxxx.pdf' chunk_size = 500 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents) keys = [] for i, doc in enumerate(docs): # Create a unique key for the document source_url = source_url.split('?')[0] filename = "/".join(source_url.split('/')[4:]) hash_key = hashlib.sha1(f"{source_url}_{i}".encode('utf-8')).hexdigest() hash_key = f"doc:{index_name}:{hash_key}" keys.append(hash_key) doc.metadata = {"source": f"[{source_url}]({source_url}_SAS_TOKEN_PLACEHOLDER_)" , "chunk": i, "key": hash_key, "filename": filename} vector_store.add_documents(documents=docs, keys=keys)
こちらを実施しましたが、以下の様に約 2MB 程度の PDF をベクトル化してインデックスに保存すると 100MB ~ 200MB 程度増えていることが分かります。
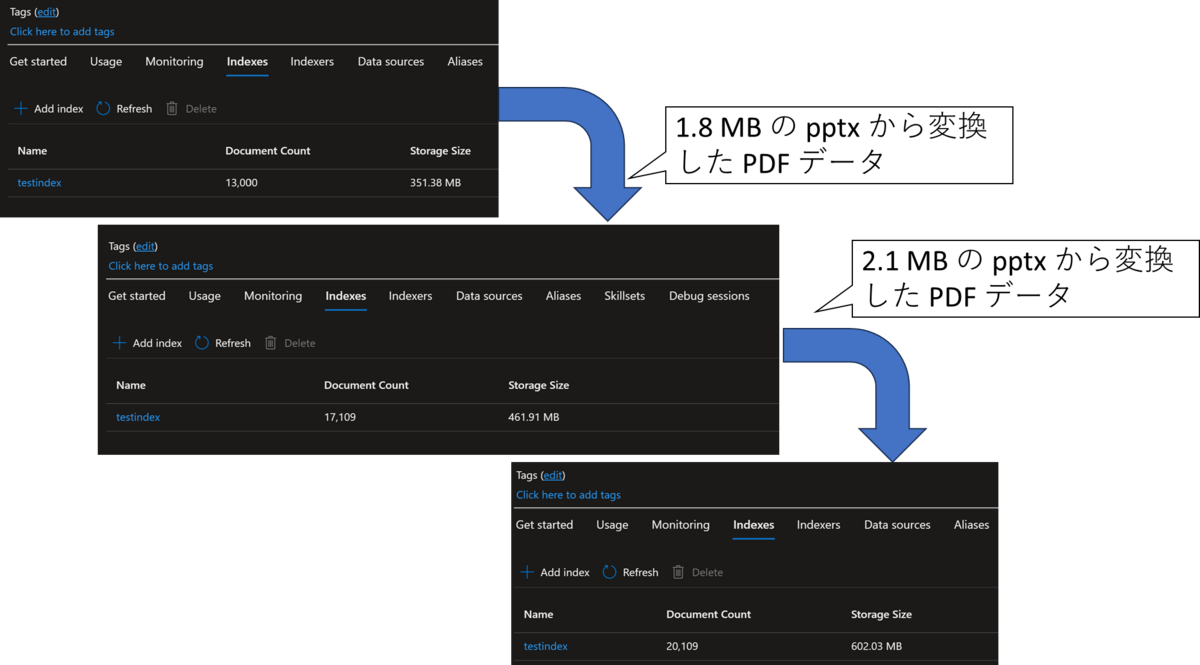
加えて、こちらの約 2MB 程度の PDF をベクトル化して Azure Cognitive Search のインデックスに保存する際、それぞれ 20 分程度の処理時間がかかりました。確認した限り、ほとんどの時間は Azure OpenAI を呼び出す Embedding の時間です。大量のドキュメントをバッチ処理したい場合等には一つの目安になると思います。
ベクトル化して保存した PDF データを用いて検索してみる
サンプルスクリプトを作成して検索を行いましたが、以下二つのスクリプトも利用しています。
- azure-open-ai-embeddings-qna/code/utilities/azuresearch.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
- azure-open-ai-embeddings-qna/code/utilities/customprompt.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
以下が今回利用したサンプルスクリプトとなります。
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.chains import ConversationalRetrievalChain from langchain.chains.qa_with_sources import load_qa_with_sources_chain from langchain.chains.llm import LLMChain from langchain.chains.chat_vector_db.prompts import CONDENSE_QUESTION_PROMPT from langchain.chat_models import AzureChatOpenAI from customprompt import PROMPT from azuresearch import AzureSearch deployment="text-embedding-ada-002" deployment_name="gpt-35-turbo" chunk_size=1 openai_api_type="azure" openai_api_key="put your Azure OpenAI key" openai_api_base="put your Azure OpenAI endpoint - https://your-azureopenai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" vector_store_address ='https://your-search-account-name.search.windows.net' vector_store_password = 'put your search account key' index_name ='put your index name' question = 'What is xxxxxx program?' prompt = PROMPT chat_history = [] embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) vector_store = AzureSearch(azure_cognitive_search_name=vector_store_address, azure_cognitive_search_key=vector_store_password, index_name=index_name, embedding_function=embeddings.embed_query) llm = AzureChatOpenAI( temperature=0, deployment_name=deployment_name, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version = openai_api_version ) question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT, verbose=False) doc_chain = load_qa_with_sources_chain(llm, chain_type="stuff", verbose=True, prompt=prompt) chain = ConversationalRetrievalChain( retriever=vector_store.as_retriever(), question_generator=question_generator, combine_docs_chain=doc_chain, return_source_documents=True, ) result = chain({"question": question, "chat_history": chat_history}) context = "\n".join(list(map(lambda x: x.page_content, result['source_documents']))) sources = "\n".join(set(map(lambda x: x.metadata["source"], result['source_documents']))) result['answer'] = result['answer'].split('SOURCES:')[0].split('Sources:')[0].split('SOURCE:')[0].split('Source:')[0] print('#### question ') print(question) print('#### answer ') print(result['answer']) print('#### context ') print(context) print('#### source ') print(sources)
実際にスクリプトを実行し、英語で記載されているセールスプログラムについての pptx ファイルを pdf ファイルに変更したものを食わせた結果、以下の様になりました。
> Finished chain. #### question What is xxxxxxxxxxxx? #### answer xxxxxxxxxxxx is a program or initiative offered by Microsoft. No further information is provided in the given text. #### context /F 4/A<</Type/Action/S/URI/URI(mailto:<中略>?subject=<中略>) >>/StructParent 9>> endobj 50 0 obj <</Type/Page/Parent 2 0 R/Resources<</ExtGState<</GS5 5 0 R/GS10 10 0 R>>/Font<</F6 52 0 R/F1 8 0 R/F7 54 0 R/F8 56 0 R/F3 19 0 R>>/ProcSet[/PDF/Text/ImageB/ImageC/ImageI] >>/MediaBox[ 0 0 960 540] /Contents 51 0 R/Group<</Type/Group/S/Transparency/CS/DeviceRGB>>/Tabs/S/StructParents 10>> endobj 51 0 obj <</Filter/FlateDecode/Length 4798>> stream <中略> endstream endobj 47 0 obj <</Type/ExtGState/BM/Normal/ca 0.74902>> endobj 48 0 obj <</Subtype/Link/Rect[ 731.83 242.6 870.68 255.35] /BS<</W 0>>/F 4/A<</Type/Action/S/URI/URI(<中略>) >>/StructParent 8>> endobj 49 0 obj <</Subtype/Link/Rect[ 733.32 64.6 905.2 79.625] /BS<</W 0>>/F 4/A<</Type/Action/S/URI/URI(<中略>) >>/StructParent 9>> endobj 50 0 obj <</Type/Page/Parent 2 0 R/Resources<</ExtGState<</GS5 5 0 R/GS10 10 0 R>>/Font<</F6 52 0 R/F <中略> #### source [https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf](https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf_SAS_TOKEN_PLACEHOLDER_)
とあるセールスプログラムについての適用条件や概要についてまとめた資料をベクトル化して保存しましたが、どこの会社が提供しているか程度でそれ以上の情報が提供されませんでした。次にもう少し踏み込んで 'What is criteria for xxxxxxxxxxxx?' を質問してみましたが、以下の様に明確な回答は得られませんでした。
Finished chain. #### question What is criteria for xxxxxxxxxxxx? #### answer The text does not provide a clear answer to this question. #### context <中略> #### source [https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf](https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf_SAS_TOKEN_PLACEHOLDER_)
pptx の様なファイルだとスライド毎に文脈が分断されやすいので、PDF データを保存する際に設定した chunk_size が 500 だと小さすぎるのかもしれません。また、日本語の PDF をそのまま入れた場合は検索に引っかからなくなったので、英語に翻訳して格納するして OpenAI の返答だけ日本語にする等の処理が必要になるかもしれません(実際には未確認)。この辺りはもうちょっと深堀して中身を確認したいと思います。
参照記事
- LangChainのTextSplitterを試す|npaka
- Azure OpenAI Service を利用したエンタープライズアーキテクチャのメモ - Qiita
- GitHub - Azure-Samples/azure-search-openai-demo: A sample app for the Retrieval-Augmented Generation pattern running in Azure, using Azure Cognitive Search for retrieval and Azure OpenAI large language models to power ChatGPT-style and Q&A experiences.
- GitHub - Azure-Samples/azure-open-ai-embeddings-qna: A simple web application for a OpenAI-enabled document search. This repo uses Azure OpenAI Service for creating embeddings vectors from documents. For answering the question of a user, it retrieves the most relevant document and then uses GPT-3 to extract the matching answer for the question.