前回は Azure Cognitive Search のベクトル検索で hello world をしてみましたが、あの程度で「これで現場で使えるな」と満足してくれる人は居ないでしょう。以下の記事ではどの様に使うかまでは踏み込みましたが、特にパラメータ設定もしてないこともあり、あまり期待する結果が得られなかったというのが現実でした。
normalian.hatenablog.com
今回は一部のパラメータを弄ってもう少し期待した結果を返してもらいたいと思います。今回は以下の部分の chunk_size と chunk_overlap に注目したいと思います。同記事はテキストデータを Azure OpenAI でEmbedding する前、テキストを一定のまとまり( chunk )にするコード片です。全体のコードを見たい方は前回の記事を参照ください。
source_url = 'https://your-storage-account-name.blob.core.windows.net/xxxxxxx/xxxxxxxxxx.pdf' chunk_size = 500 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents)
chunk_size と chunk_overlap って何?
ここが分からないとパラメータを変更をしても何が何やら分からなくなってしまうので、まずこのパラメータが何をしているかを確認しましょう。そのためには以下の記事が参考になります。そこには「TokenTextSplitter splits a raw text string by first converting the text into BPE tokens」という記載があり、BPE トークンと呼ばれるものに文字列を変換する模様です。
js.langchain.com
では BPE トークンが何かというと今度は以下の記事が参考になり、BPE は Bite Pair Encoding の略であり、頻出する文字列の組み合わせからその分割方法を学習するものだそうです。
cardinal-moon.hatenablog.com
そろそろ用語のキャッチアップばかりで疲れてきたと思いますので、以下のコードで実際に確かめてみましょう。サンプル文字列に対して chunk_size と chunk_overlap を設定しています。
from langchain.text_splitter import TokenTextSplitter, TextSplitter
text = "I often hear opinions similar to 'Is there any innovative business that offers high profits without risks?', but it sounds like same opinion with high school girls who want to lose weight but still crave sweet treats."
chunk_size = 10
chunk_overlap = 3
text_splitter: TextSplitter = TokenTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
encoding_name="gpt2")
output = text_splitter.create_documents([text])
print(output)こちらの結果は以下の様になります。実際には一行で出ていますが、読みやすい様に改行しているのでご注意ください。
PS C:\opt\workspace\Test-VectorSearch> python .\test_splitter.py
[Document(page_content="I often hear opinions similar to 'Is there any", metadata={}),
Document(page_content='Is there any innovative business that offers high profits without', metadata={}),
Document(page_content=" high profits without risks?', but it sounds like", metadata={}),
Document(page_content=' it sounds like same opinion with high school girls who', metadata={}),
Document(page_content=' school girls who want to lose weight but still crave', metadata={}),
Document(page_content=' but still crave sweet treats.', metadata={})]
PS C:\opt\workspace\Test-VectorSearch> 上記を見て頂ければ分かると思いますが、設定した chunk_size(=10 単語)以下でひとまとまりにされ、設定した chunk_overlap(= 3 単語)で前後の chunk と重複していることが分かります。
では日本語ではどうなるのでしょうか?殆どの読者各位は日本語での内容が気になると思いますので、当該英文を日本語に直して試してみたいと思います。実行したのは以下のコードで内容は変えていません。
from langchain.text_splitter import TokenTextSplitter, TextSplitter
text = "「リスクなしに高収益が得られる革新的なビジネスはないのか」というような意見をよく耳にするが、「痩せたいけど甘いものが食べたい」という女子高生と同じ意見に聞こえる。"
chunk_size = 10
chunk_overlap = 3
text_splitter: TextSplitter = TokenTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
encoding_name="gpt2")
output = text_splitter.create_documents([text])
print(output)実行結果は以下になります。こちらも実際には一行で出ていますが、読みやすい様に改行しているのでご注意ください。
PS C:\opt\workspace\Test-VectorSearch> python .\test_splitter.py
[Document(page_content='「リスクなしに高�', metadata={}),
Document(page_content='高収益が得ら', metadata={}),
Document(page_content='得られる革新', metadata={}),
Document(page_content='�新的なビジネスは', metadata={}),
Document(page_content='ネスはないのか」とい', metadata={}),
Document(page_content='」というような意', metadata={}),
Document(page_content='な意見をよく�', metadata={}),
Document(page_content='�く耳にするが、「', metadata={}),
Document(page_content='が、「痩せたい', metadata={}),
Document(page_content='�たいけど甘い', metadata={}),
Document(page_content='甘いものが食べ', metadata={}),
Document(page_content='�べたい」という女', metadata={}),
Document(page_content='いう女子高生と同', metadata={}),
Document(page_content='と同じ意見に', metadata={}),
Document(page_content='見に聞こえる', metadata={}),
Document(page_content='える。', metadata={})]御覧の通り、日本語の方が分割数が多いのが確認できると思います。英語や多くのヨーロピアン言語と異なり、日本語を含むアジア圏の国は「スペースで単語を区切る」という言語構造をしていないこともあり、こうした分割時には言語固有の癖が出ているのが確認できます。設定した chunk_size や chunk_overlap からするとやや文字数が少ない様に見受けられるのですが、単にマルチバイト文字だからなのかこの辺りはもしわかる方がコメント頂ければ幸いです。
chunk_size を変えて試してみる
では次に実際のデータを食わせて考えてみましょう今回は以下のPDF ファイル(に似たものを厳密には利用しています) を試したいと思います。ずいぶん前になりますが、Azure における EA と CSP における subscription 管理についてまとめた資料になります。こちらは EA や CSP とは何か?に加え、Microsoft アカウントと組織アカウントについて、一つの Azure AD テナントに複数の EA/CSP subscription がつけられるか等がまとまっています。
それぞれ以下のパラメータで Azure Cognitive Search 上でインデックスを作成してみました。
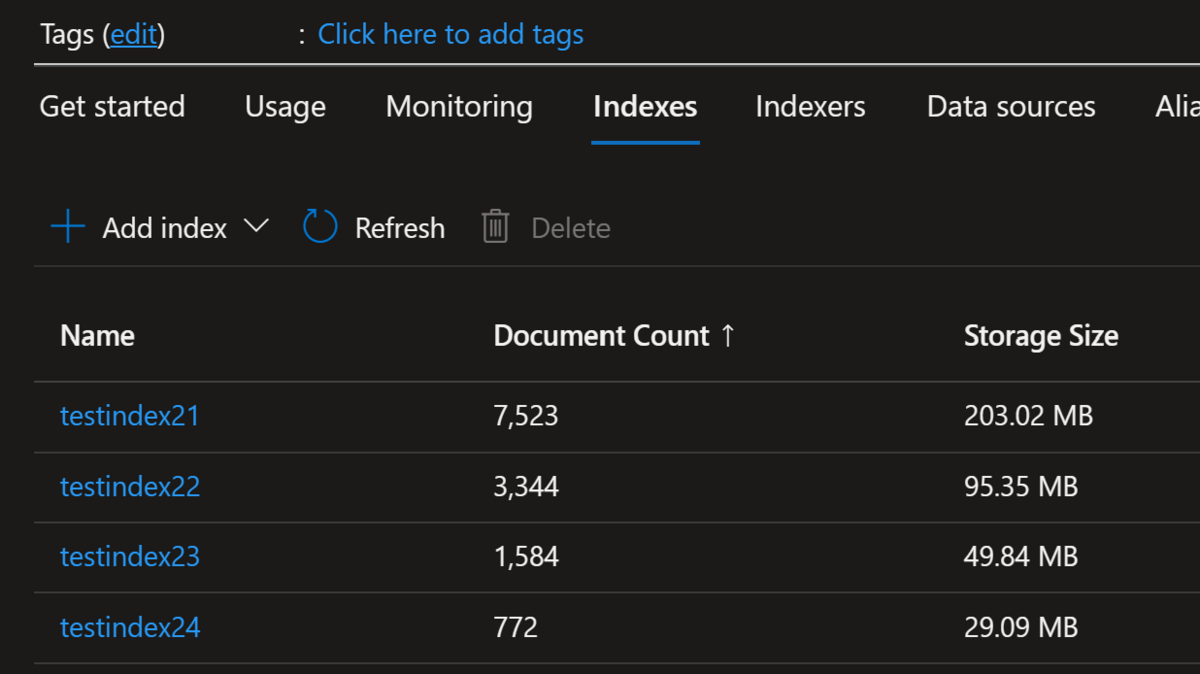
- testindex21: chunk_size = 500, chunk_overlap = 100 のケース
- testindex22: chunk_size = 1000, chunk_overlap = 100 のケース
- testindex23: chunk_size = 2000, chunk_overlap = 100 のケース
- testindex24: chunk_size = 4000, chunk_overlap = 100 のケース
数字を見ればご認識頂けると思いますが、chunk_size を大きくした分だけまとまりが大きくなっているので、その分だけ Azure Cognitive Search のドキュメント数が少なくなり、加えて冗長分が減っただけデータサイズも小さくなっています。
次に実際にクエリを発行してみましょう。抜粋するとコード片は以下です(※全体を見たい場合は前回の記事を参照下さい)。
index_name ='testindex21' # 'testindex22', 'testindex23', 'testindex24' question = 'What is best practice to leverage both EA and CSP for a customer?' prompt = PROMPT chat_history = [] (中略) question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT, verbose=False) doc_chain = load_qa_with_sources_chain(llm, chain_type="stuff", verbose=True, prompt=prompt) chain = ConversationalRetrievalChain( retriever=vector_store.as_retriever(), question_generator=question_generator, combine_docs_chain=doc_chain, return_source_documents=True, max_tokens_limit=7000 ) result = chain({"question": question, "chat_history": chat_history}) context = "\n".join(list(map(lambda x: x.page_content, result['source_documents']))) sources = "\n".join(set(map(lambda x: x.metadata["source"], result['source_documents']))) result['answer'] = result['answer'].split('SOURCES:')[0].split('Sources:')[0].split('SOURCE:')[0].split('Source:')[0] print('#### source ') print(sources) print('#### question ') print(question) print('#### answer ') print(result['answer'])
各処理結果を見てみましょう。
testindex21: chunk_size = 500, chunk_overlap = 100 のケース
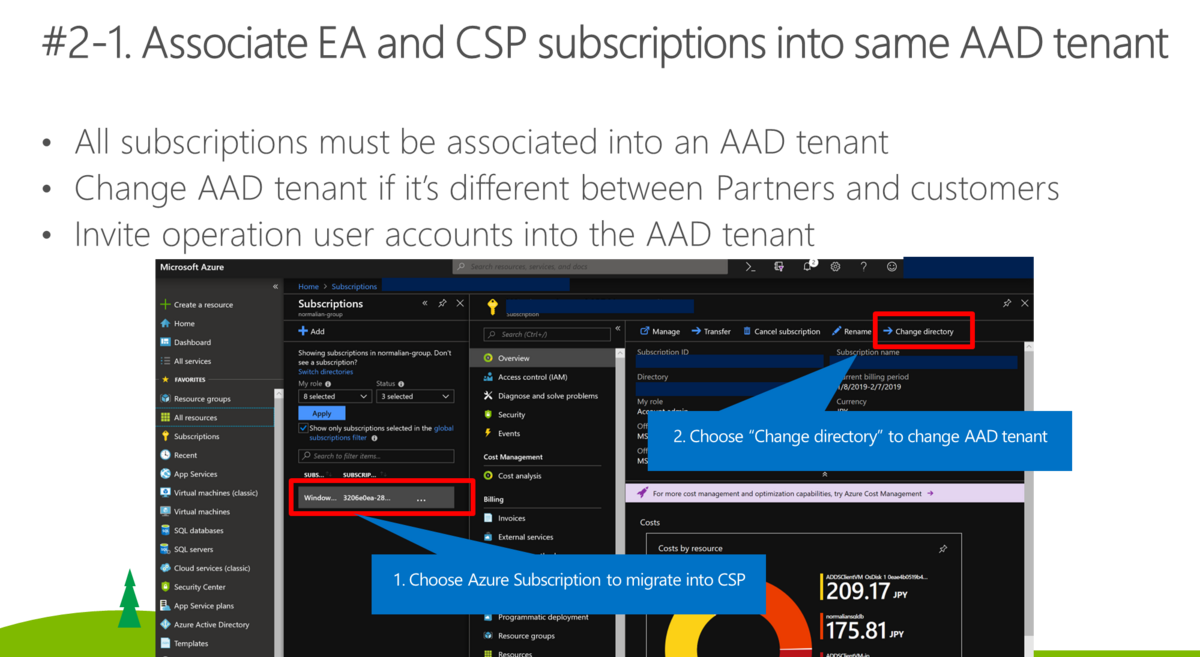
index_name ='testindex21' #### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to associate their EA and CSP subscriptions into the same AAD tenant and perform a migration assessment for using Azure resources. (Slide 42)
御覧の様にかなり簡潔な答えが返ってきます。スライド番号まで示してくれているので確認したところ、以下のスライドなのでかなりいい線に行っている気がしますが、別に migration assessment は必須ではないのでどこかで意味が混じっている気がします。
testindex22: chunk_size = 1000, chunk_overlap = 100 のケース
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to associate EA and CSP subscriptions into the same AAD tenant and perform a migration assessment for using Azure resources. (Slide 42)
こちらは殆ど結果は一緒です。やや文言は異なりますが、同じ内容が帰ってきていると言い切って問題ないでしょう。
testindex23: chunk_size = 2000, chunk_overlap = 100 のケース
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to use EA for centralized management and governance of Azure subscriptions, and CSP for flexible and scalable purchasing and support options for individual customers. (
こちらの結果では CSP の説明に重きを置いた結果が返ってきていますが、参照スライド番号が消えてしまっています。こちらはちょっとイマイチな結果になっていると言っていいでしょう。
testindex24: chunk_size = 4000, chunk_overlap = 100 のケース
resp, got_stream = self._interpret_response(result, stream)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\daisami\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\openai\api_requestor.py", line 624, in _interpret_response
self._interpret_response_line(
File "C:\Users\daisami\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\openai\api_requestor.py", line 687, in _interpret_response_line
raise self.handle_error_response(
openai.error.InvalidRequestError: This model's maximum context length is 8192 tokens. However, your messages resulted in 16409 tokens. Please reduce the length of the messages.こちらではエラーとなってしまいました。どうやらモデルの context length を超えてしまったようです。エラー回避のために以下の様にコードを変更しました。
chain = ConversationalRetrievalChain(
retriever=vector_store.as_retriever(),
question_generator=question_generator,
combine_docs_chain=doc_chain,
return_source_documents=True,
max_tokens_limit=7000
)
結果で帰ってきた内容は以下となります。
#### source [https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf](https://xxxxxxxxxxxx.blob.core.windows.net/shared/Azure%20Subscription%20Management%20with%20EA%20and%20CSP.pdf_SAS_TOKEN_PLACEHOLDER_) #### question What is best practice to leverage both EA and CSP for a customer? #### answer The best practice to leverage both EA and CSP for a customer is to use the EA for centralized billing and management of large-scale workloads, and CSP for agile and flexible management of smaller workloads. (
三つ目のケースと似たような内容が帰ってきています。
結果
御覧の様に chunk サイズを伸ばしても結果が洗練されるわけではないということが分かりました。今回は英語で chunk_size を 500 としましたが、英語では500単語という意味なるので、最初からやや大き目な chunk_size だったのかなと思います。
日本語で実施した場合は chunk_size は大き目にしないと文脈を失う可能性がありそうですが、chunk_size を大きくしすぎると token 数の制限に引っかかってしまう点にも注意です。