2023 年 5 月に実施された Microsoft Build というイベントで Azure Cognitive Search にベクトル検索機能が private preview で追加されました。同機能単体で見ると「?」な人も居ると思いますが、Azure OpenAI と組みあわせることで強力な力を発揮します。この辺りの詳細については以下の Qiita 記事が非常に良くまとまっています。
qiita.com
qiita.com
OpenAI 単体でも様々なことが実現可能ですが、社畜業を営む我々としては「俺たちの内部データを使ってもっと OpenAI の回答をカスタマイズできないのか?ただし閉域網でな!!」という「ダイエットしたいけど甘いものが食べたい」的なことがが気になって仕方がないことでしょう。閉域網に関しては単に private endpoint 等の Azure VNET の機能を活用すれば何とかなるので割愛しますが、元々要件を達成するにはテキストの 埋め込み が非常に重要になります。Azure OpenAI では Embeddings API を利用し、テキストをベクトル化することでテキスト間の類似性をコサイン類似度と呼ばれる尺度ではかることができます。
そもそも Azure Cognitive Search のベクトル検索機能って今使えるの?
Microsoft Build 2023 で発表された機能ですが、2023 年 6 月 19 日現在では private preview 機能となりますがリージョン指定は特にないので、日本のリージョン(東日本は試しました)で利用可能です。現在は以下のフォームを埋めて private preview に参加依頼を出す必要があります。
https://aka.ms/VectorSearchSignUp
フォームを埋めたりというと心理障壁があると思いますが、フォームを埋めた数十分くらいで以下のメールが来てあっという間に機能が有効化されたので、使いたかったらとりあえず試してみるのはお勧めです。
PDF データをベクトル化して Azure Search のインデックスに保存してみる
参考にしたサンプルは以下のサンプルとなります。
github.com
特に以下の Azure Cognitive Search に関する helper クラスに関してはそのまま流用しました。
azure-open-ai-embeddings-qna/code/utilities/azuresearch.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
ベクトル検索の設定に関しては特に以下の行周辺が参考になります。
https://github.com/Azure-Samples/azure-open-ai-embeddings-qna/blob/main/code/utilities/azuresearch.py#L83
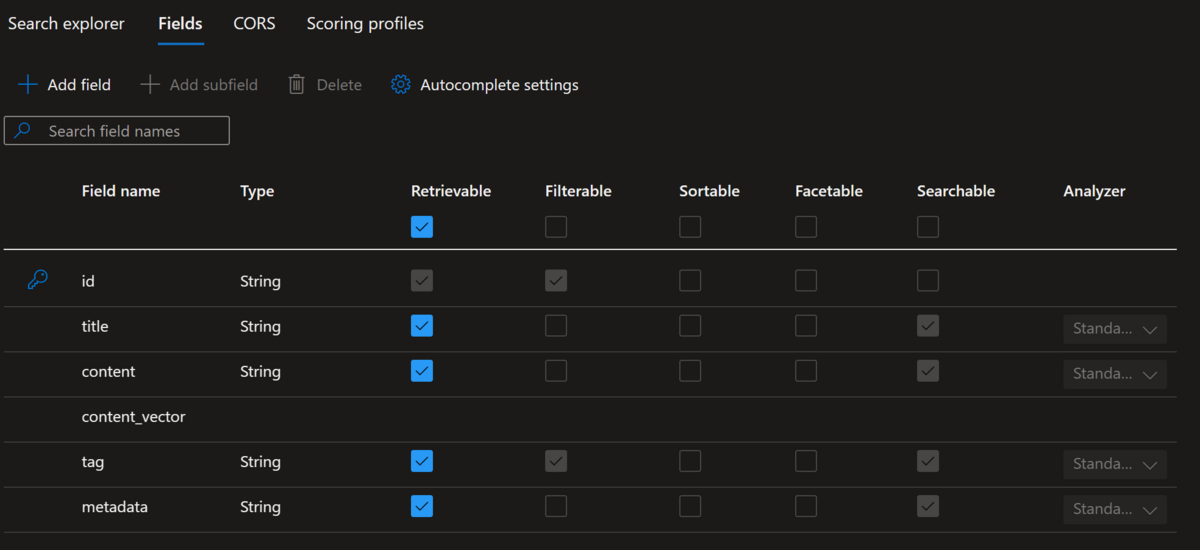
現時点で Azure Portal 上ではベクトル検索のフィールドは作成することはできませんが、上記の python スクリプトを用いてインデックスを作成すると Azure Portal では以下の様に表示されます。
では実際に pptx ファイルを pdf ファイルとして Azure Blob Storage に保管し、Azure OpenAI では Embeddings API を利用してテキストをベクトル化し、Azure Cognitive Search のインデックスに保存します。上記の通り Azure Cognitive Search に関する helper クラスを丸々流用しているので、以下を実際に動かす際はそちらも確認下さい。
from azuresearch import AzureSearch from langchain.embeddings.openai import OpenAIEmbeddings from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import TokenTextSplitter, TextSplitter import hashlib deployment="text-embedding-ada-002" # put your deployment name chunk_size=1 openai_api_type="azure" openai_api_key="put your Azure OpenAI key" openai_api_base="put your Azure OpenAI endpoint - https://your-azureopenai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" vector_store_address ='https://your-search-account-name.search.windows.net' vector_store_password = 'put your search account key' index_name ='put your index name' embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) vector_store = AzureSearch(azure_cognitive_search_name=vector_store_address, azure_cognitive_search_key=vector_store_password, index_name=index_name, embedding_function=embeddings.embed_query) source_url = 'https://your-storage-account-name.blob.core.windows.net/xxxxxxx/xxxxxxxxxx.pdf' chunk_size = 500 chunk_overlap = 100 document_loaders = WebBaseLoader text_splitter: TextSplitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) documents = document_loaders(source_url).load() docs = text_splitter.split_documents(documents) keys = [] for i, doc in enumerate(docs): # Create a unique key for the document source_url = source_url.split('?')[0] filename = "/".join(source_url.split('/')[4:]) hash_key = hashlib.sha1(f"{source_url}_{i}".encode('utf-8')).hexdigest() hash_key = f"doc:{index_name}:{hash_key}" keys.append(hash_key) doc.metadata = {"source": f"[{source_url}]({source_url}_SAS_TOKEN_PLACEHOLDER_)" , "chunk": i, "key": hash_key, "filename": filename} vector_store.add_documents(documents=docs, keys=keys)
こちらを実施しましたが、以下の様に約 2MB 程度の PDF をベクトル化してインデックスに保存すると 100MB ~ 200MB 程度増えていることが分かります。
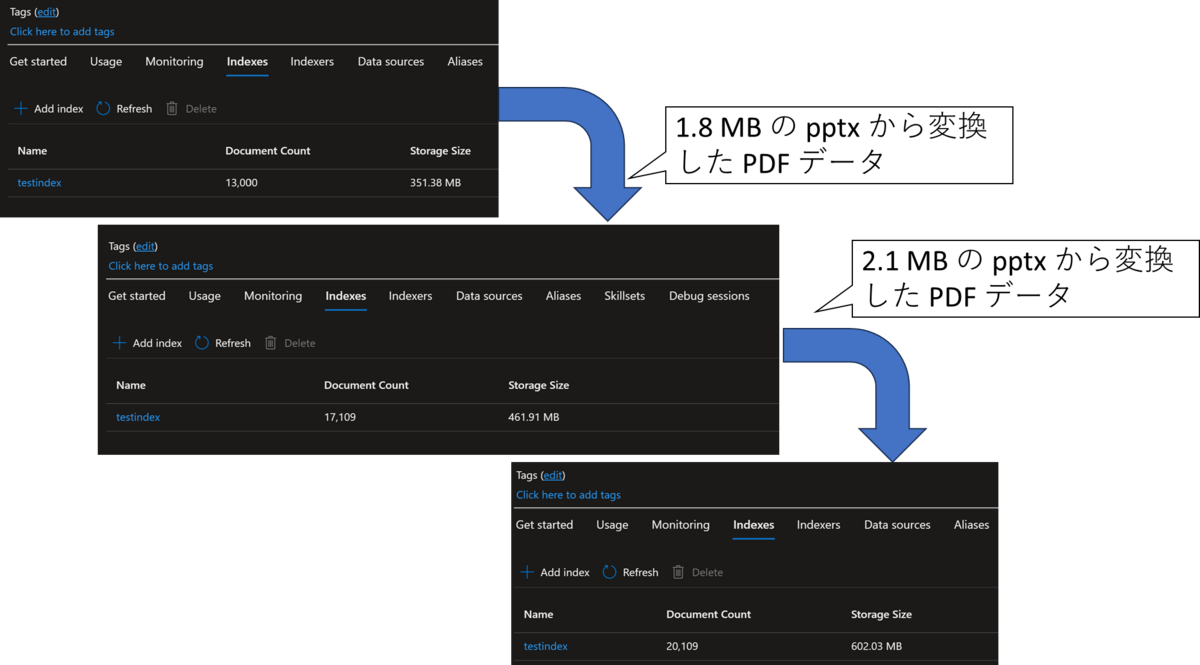
加えて、こちらの約 2MB 程度の PDF をベクトル化して Azure Cognitive Search のインデックスに保存する際、それぞれ 20 分程度の処理時間がかかりました。確認した限り、ほとんどの時間は Azure OpenAI を呼び出す Embedding の時間です。大量のドキュメントをバッチ処理したい場合等には一つの目安になると思います。
ベクトル化して保存した PDF データを用いて検索してみる
サンプルスクリプトを作成して検索を行いましたが、以下二つのスクリプトも利用しています。
- azure-open-ai-embeddings-qna/code/utilities/azuresearch.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
- azure-open-ai-embeddings-qna/code/utilities/customprompt.py at main · Azure-Samples/azure-open-ai-embeddings-qna · GitHub
以下が今回利用したサンプルスクリプトとなります。
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.chains import ConversationalRetrievalChain from langchain.chains.qa_with_sources import load_qa_with_sources_chain from langchain.chains.llm import LLMChain from langchain.chains.chat_vector_db.prompts import CONDENSE_QUESTION_PROMPT from langchain.chat_models import AzureChatOpenAI from customprompt import PROMPT from azuresearch import AzureSearch deployment="text-embedding-ada-002" deployment_name="gpt-35-turbo" chunk_size=1 openai_api_type="azure" openai_api_key="put your Azure OpenAI key" openai_api_base="put your Azure OpenAI endpoint - https://your-azureopenai-endpoint.openai.azure.com" openai_api_version="2023-03-15-preview" vector_store_address ='https://your-search-account-name.search.windows.net' vector_store_password = 'put your search account key' index_name ='put your index name' question = 'What is xxxxxx program?' prompt = PROMPT chat_history = [] embeddings = OpenAIEmbeddings( deployment=deployment, chunk_size=chunk_size, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version=openai_api_version) vector_store = AzureSearch(azure_cognitive_search_name=vector_store_address, azure_cognitive_search_key=vector_store_password, index_name=index_name, embedding_function=embeddings.embed_query) llm = AzureChatOpenAI( temperature=0, deployment_name=deployment_name, openai_api_type=openai_api_type, openai_api_key=openai_api_key, openai_api_base=openai_api_base, openai_api_version = openai_api_version ) question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT, verbose=False) doc_chain = load_qa_with_sources_chain(llm, chain_type="stuff", verbose=True, prompt=prompt) chain = ConversationalRetrievalChain( retriever=vector_store.as_retriever(), question_generator=question_generator, combine_docs_chain=doc_chain, return_source_documents=True, ) result = chain({"question": question, "chat_history": chat_history}) context = "\n".join(list(map(lambda x: x.page_content, result['source_documents']))) sources = "\n".join(set(map(lambda x: x.metadata["source"], result['source_documents']))) result['answer'] = result['answer'].split('SOURCES:')[0].split('Sources:')[0].split('SOURCE:')[0].split('Source:')[0] print('#### question ') print(question) print('#### answer ') print(result['answer']) print('#### context ') print(context) print('#### source ') print(sources)
実際にスクリプトを実行し、英語で記載されているセールスプログラムについての pptx ファイルを pdf ファイルに変更したものを食わせた結果、以下の様になりました。
> Finished chain. #### question What is xxxxxxxxxxxx? #### answer xxxxxxxxxxxx is a program or initiative offered by Microsoft. No further information is provided in the given text. #### context /F 4/A<</Type/Action/S/URI/URI(mailto:<中略>?subject=<中略>) >>/StructParent 9>> endobj 50 0 obj <</Type/Page/Parent 2 0 R/Resources<</ExtGState<</GS5 5 0 R/GS10 10 0 R>>/Font<</F6 52 0 R/F1 8 0 R/F7 54 0 R/F8 56 0 R/F3 19 0 R>>/ProcSet[/PDF/Text/ImageB/ImageC/ImageI] >>/MediaBox[ 0 0 960 540] /Contents 51 0 R/Group<</Type/Group/S/Transparency/CS/DeviceRGB>>/Tabs/S/StructParents 10>> endobj 51 0 obj <</Filter/FlateDecode/Length 4798>> stream <中略> endstream endobj 47 0 obj <</Type/ExtGState/BM/Normal/ca 0.74902>> endobj 48 0 obj <</Subtype/Link/Rect[ 731.83 242.6 870.68 255.35] /BS<</W 0>>/F 4/A<</Type/Action/S/URI/URI(<中略>) >>/StructParent 8>> endobj 49 0 obj <</Subtype/Link/Rect[ 733.32 64.6 905.2 79.625] /BS<</W 0>>/F 4/A<</Type/Action/S/URI/URI(<中略>) >>/StructParent 9>> endobj 50 0 obj <</Type/Page/Parent 2 0 R/Resources<</ExtGState<</GS5 5 0 R/GS10 10 0 R>>/Font<</F6 52 0 R/F <中略> #### source [https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf](https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf_SAS_TOKEN_PLACEHOLDER_)
とあるセールスプログラムについての適用条件や概要についてまとめた資料をベクトル化して保存しましたが、どこの会社が提供しているか程度でそれ以上の情報が提供されませんでした。次にもう少し踏み込んで 'What is criteria for xxxxxxxxxxxx?' を質問してみましたが、以下の様に明確な回答は得られませんでした。
Finished chain. #### question What is criteria for xxxxxxxxxxxx? #### answer The text does not provide a clear answer to this question. #### context <中略> #### source [https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf](https://yyyyyyyyyyyy.blob.core.windows.net/shared/yyyyyyyyyyyy%20Partner%20briefing%20deck%20v1.2.pdf_SAS_TOKEN_PLACEHOLDER_)
pptx の様なファイルだとスライド毎に文脈が分断されやすいので、PDF データを保存する際に設定した chunk_size が 500 だと小さすぎるのかもしれません。また、日本語の PDF をそのまま入れた場合は検索に引っかからなくなったので、英語に翻訳して格納するして OpenAI の返答だけ日本語にする等の処理が必要になるかもしれません(実際には未確認)。この辺りはもうちょっと深堀して中身を確認したいと思います。
参照記事
- LangChainのTextSplitterを試す|npaka
- Azure OpenAI Service を利用したエンタープライズアーキテクチャのメモ - Qiita
- GitHub - Azure-Samples/azure-search-openai-demo: A sample app for the Retrieval-Augmented Generation pattern running in Azure, using Azure Cognitive Search for retrieval and Azure OpenAI large language models to power ChatGPT-style and Q&A experiences.
- GitHub - Azure-Samples/azure-open-ai-embeddings-qna: A simple web application for a OpenAI-enabled document search. This repo uses Azure OpenAI Service for creating embeddings vectors from documents. For answering the question of a user, it retrieves the most relevant document and then uses GPT-3 to extract the matching answer for the question.